

Listen in on my conversation with Zhamak Dehghani, a leading expert on distributed systems and big data architecture and decentralized technology solutions. We talked about the concept of Data Mesh that she introduced in 2018 in her paper, “Beyond the Data Lake.” We also discuss key principles of the Data Mesh approach and how domain ownership can change how companies think about and manage their data responsibilities.
Zhamak has been a software engineer for 20 years and works at ThoughtWorks as the Director of Emerging Technology. She has many achievements to her name, such as contributing to multiple patents in distributed computing communications, being a member of the ThoughtWorks technology advisory board, and contributing to the creation of ThoughtWorks Technology Radar.
She is the founder of an approach for sourcing, managing and accessing analytical data called Data Mesh. Her ideas are starting to revolutionize how companies interact with their data to move them towards decision-making based on data-driven predictions rather than a “gut-feel” decision.
Zhamak Dehghani and I talked in this episode on the Open Source Data podcast and how Data Mesh is the approach to solve many of the problems experienced in practice big data architecture.
With all the recent advances in machine learning and artificial intelligence, more and more companies aim to harness this power to get more analytical insights into their data.
Operational and analytical data generally take place in separate silos. The integration architecture between the two can be fragile, leading to duplicate and irrelevant data, long-running and inefficient queries and poorly mapped data. The side effects are waste: compute, storage, and the irreplaceable heartbeats of the people trying to make these systems work to drive decisions.
There is another way. In her paper, Beyond The Lake, Zhamak introduces a new concept called Data Mesh, a solution to unlock the value from data and make it more accessible.
A Data Mesh is an architectural approach to go from a monolithic data platform, common within big companies, and move towards a decentralized solution. To decentralize, each domain within a company takes responsibility for their data to ensure it’s of good quality and consumable.
In our conversation, we talked about the origins of Data Mesh, the main four principles, and the vision of the future.
The origins of Data Mesh
Zhamak’s clients spanned several industries, including healthcare, retail, and technology. One thing they all had in common was that they were rich in domains - they had a deep knowledge of specific customer needs, regulations, and business processes. However, despite their wealth of data, they struggled with extracting its value. These domains weren’t owned and offered across their companies as data products, so instead of representing opportunity, the diversity of disconnected domains made it harder to be data-driven enterprises.
Zhamak tells us, “...the technology and approach and solutioning and mindset were really probably a decade behind what I had seen in an operational world.”
Advancements in other fields to decentralize and democratize, similar to what happened with microservices and Kubernetes, and inspiration from reading Thomas Kuhn and his ideas on paradigm shifts within scientific fields, let Zhamak see an opportunity to plunge into turmoil, to rock the current status-quo in big data analytics.
Zhamak wrote an introductory paper called Beyond The Lake, her ontology of architectural practice to create what would later be named Data Mesh.
Data mesh principles
Four principles are needed to implement a Data Mesh approach to improve the ease of getting value from analytical data at scale.
Domain ownership
Domain ownership is the main principle of the Data Mesh approach. It’s the idea of decentralizing the way data is analyzed and consumed, and distributing the responsibility to the people closest to the data most familiar with it.
It takes away the data flow in a central location such as a Data Lake and lets the domains host and efficiently serve each of their datasets.
Data as a product
The monolithic approach of data flowing from domains into a central data lake to consume has challenges.
- It’s possible there could be duplications of data due to the number of domains the data lake is receiving data from.
- Gartner refers to “dark data”, where a company collects data that is never used. The data comes at a cost to store and could pose a security risk for no reason.
- The data could be of poor quality, inconsistent formatting, and missing or inaccurate data that has been updated or is plain wrong.
The second principle, data as a product, will help solve some of the above issues, reducing the friction and the cost of using data. With each domain taking responsibility for their data, when the data analysts or scientists come to consume it, they can be sure they are getting exactly what they need - a valuable and consumable product.
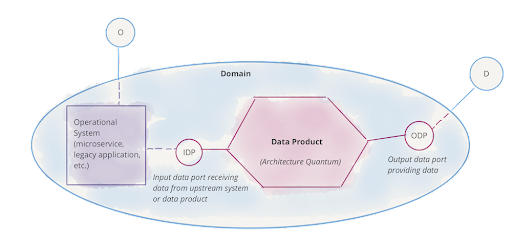
Figure 1: The domain as an operational system and analytical data product
Assigning a data product developer role will help each domain build, maintain and serve the domain's data and be responsible that the analysts can get the correct value out of the data.
Zhamak mentions in the podcast that with each domain building its microservices and its data products, it's a space where you can expect some innovation.
Self-serve data platform
When first presented with the Data Mesh approach, it can be pretty daunting. It can look like an unnecessary cost for companies, introducing new roles and duplicating them across domains.
But as Zhamak said, “...over the next decade, it's embarrassingly obvious that Machine Learning is going to transform every organization in the world.” And if the capabilities aren’t there to unlock the data, there’ll be missed opportunities for data-driven insights.
The third principle, a self-serve data platform, helps reduce this concern. It’s fundamental to leverage technologies that can automate the work required to offer data as a product. So data can be more easily provided to be consumed and maintained with reduced effort.
Federated computational governance
The approach of the responsibilities of data by the domains could lead to independent decision-making that could affect the whole organization.
Having a team that can discuss policies at a global and domain level will let companies discover the impact these decisions could have and is why the fourth principle of Data Mesh, federated computational governance, is essential.
Zhamak said, “We need a new model for governing data at scale when it's decentralized.” She mentions, “the past paradigms around governance, being very much centralized. You have a centralized team with a lot of manual effort, they try to enforce and control the policies.” The centralized approach to governance often causes friction and frustration for people wanting to use the data.
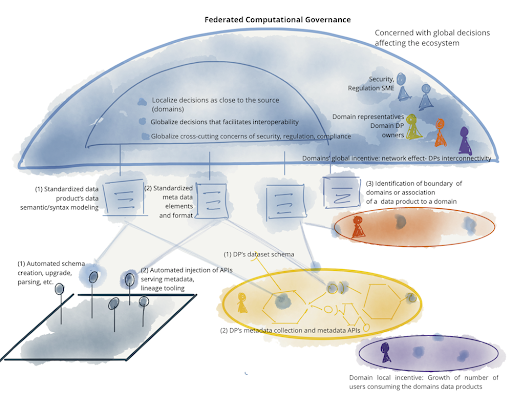
Figure 2: Example of elements of a federated computational governance
Federated computational governance allows for more flexibility among the domains. There might be certain decisions that work in one domain and not in another. So rather than forcing decisions across the whole company, they can be kept locally.
There should be representatives from each domain deciding the global policies, so the policy's impact at the domain level can be apparent.
Overall, leveraging data mesh oriented technology to automate these policy decisions will ensure consistency within each domain and across the company.
Domain ownership deeper dive
In the podcast episode, we talked more deeply about the most important Data Mesh principle, domain ownership.
Zhamak spoke about how she saw a real-life example of Conway’s law in different organizations. Conway’s law holds that the way software is built mirrors the structure of the organization. If you have an organization that answers to only one person, you can expect to find a monolithic structure.
When you have numerous domains in a monolithic structure, things become tricky when you want to analyze and get value out of your data. The first principle of Data Mesh, domain ownership, helps to resolve this problem.
“I think the very first pillar or principle under data mesh is the decentralization of the data ownership as well as architecting around the boundary of domains, and giving that responsibility and accountability to the people who are most intimately familiar with that data.”
The idea is to decentralize and distribute the responsibility of the data, making the people who are closest to the data the guardians of it. It’s their job to make sure the data is clean, easy to use and understandable.
The second principle of Data Mesh helps to achieve this by treating the data as a product. This shift in mindset treats the data scientists, machine learning and data engineers as customers, and it's the people in their domains to make sure they deliver consumable quality data.
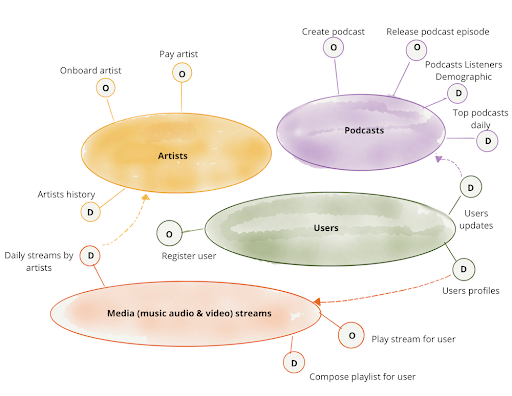
Figure 3: An example of domain-oriented ownership
Companies can then move from the typical monolithic data lake, where the ownership is scattered among different departments, to a decentralized landscape where the experts manage their data and make it more broadly available within the organization.
Enjoy the conversation? Subscribe to the Open||Source||Data podcast so you never miss an episode. And, follow the DataStax Tech Blog for more developer stories!
Resources
More Company
View All
Shaping the Wild in Las Vegas: An AWS re:Invent Recap

Announcing 12 Days of Codemas: The DataStax Holiday Giveaway!

London Called. RAG++, The AI Event, Answered!
