



Welcome to Part 5 of a six-part series on Apache Cassandra®. We introduced you to a few powerful Cassandra features in Part 1 and showed you how to model data on NoSQL databases in Part 2. In Part 3 and Part 4, we discussed benchmarking your database and Storage-Attached Indexes.
In the next two posts, we’ll show you how you can migrate your existing SQL-based applications to NoSQL, the practical implications to your data model, and how you can flip the switch between the two once your new system is in place. We’ll walk you through the process of using the PetClinic Spring reference application and the robust, open-source NoSQL database: Apache Cassandra, trusted by thousands of companies around the world for mission-critical, high-growth, real-time applications.
Cassandra is the only distributed NoSQL database that delivers the always-on availability, blisteringly fast read-write performance, and unlimited linear scalability needed to meet the demands of successful modern applications. The easiest way to spin up a fully-realized Cassandra database is through DataStax Astra DB, a multi-cloud database-as-a-service.
The three approaches we’ll cover in this post are:
1) Offline migration
2) Zero-downtime migration with shadow writes
3) Minimal-downtime migration with dual reads
Why switch from SQL to NoSQL?
For most of you, you probably learned about relational databases first. Relational databases are very powerful because they ensure consistency and availability at the same time. They are super effective and easy as long as you have your databases running on the same machine.
But if you need to run more transactions or need more space to store your data, there are upper limits to how far you can vertically scale on a single machine. The problem arises: relational databases aren’t able to scale efficiently.
The solution to scale out is to split the data among multiple machines, creating a distributed system. In fact, NoSQL databases were invented to cope with these new requirements of volume (capacity), velocity (throughput) and variety (format) of big data.
With the rise of Big Tech, the global datasphere skyrocketed 15-fold in the last decade. And relational databases simply weren’t ready to cope with the new data volume or new performance requirements. Huge global operations like Google, Facebook or LinkedIn create and use NoSQL databases to scale efficiently, go global, and achieve zero downtime.
Cassandra, like many other NoSQL databases, is governed by the CAP Theorem. The theorem states that a distributed database system can only guarantee two out of these three characteristics in case of a network failure scenario: Consistency, Availability, and Partition Tolerance.
Cassandra is usually described as an “AP” system, meaning it errs on the side of ensuring data availability even if this means sacrificing consistency. But that’s not the whole picture. Cassandra is configurably consistent: you can set the Consistency Level you require and tune it to be more AP or CP according to your use case.
Head over to this YouTube video for a more in-depth breakdown of SQL and NoSQL databases.
Defining the migration problem
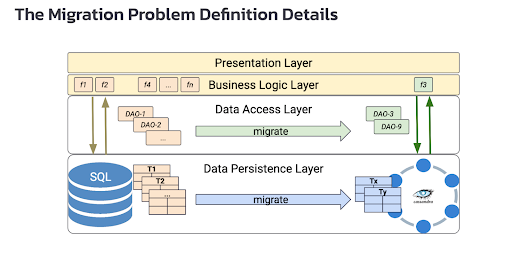
Figure 1. Migration problem defined in detail.
Migrating from SQL to NoSQL can feel like a slide puzzle game where you have to reason out the order of operations to get it right. Although there are multiple options for migration, our goal is to help you puzzle out a complete picture.
In an ideal world, your applications on relational databases don’t run into any issues and there’s no need to switch them over to NoSQL. But if you run into scalability issues, or if you ever need to go global, then you have some great reasons to migrate. Cassandra partitions over distributed architecture to handle petabytes of data for linear scalability and replicates data on multiple centers around the world, keeping up with your data needs.
Imagine how easy it would be if you can just take the old application, rewrite parts of it, and migrate your schema and data to get your new application. But that’s not how it works in reality, because a relational database contains hundreds of tables, with different applications using them for different business functions.
Migrating the whole application can take a long time, during which application and data requirements might change. As the application and relational database evolves, your migration has to pick up the evolution, becoming way too complex.
A more realistic approach is to take a small piece of a larger application, say, a feature or business function that only uses 20 or 50 tables in a relational database, and migrate it to NoSQL in a reasonable amount of time. To understand this, let’s look at the four layers in data architecture.
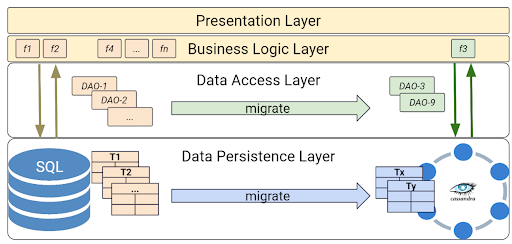
Figure 2. Four-layer data architecture.
- Presentation layer displays information to and collects information from users.
- Business logic layer acts as an intermediary for data exchange between the presentation layer and the data access layer. It handles the business rules that determine how data is created, stored, and changed.
- Data access layer facilitates access between applications and any type of persistent storage, in this case, SQL and NoSQL databases.
- Data persistence layer is the actual database consisting of schemas and tables.
When we migrate a business function, its business logic isn’t likely to change except in rare cases. There are certain features in the relational database that don’t map exactly to a NoSQL database—like asset transactions, for example.
But most of the time, what will change is data access objects, which now have to interact with Cassandra. You’ll also need to migrate data persistence layers, or schema and tables, from SQL to NoSQL.
Approach 1: offline migration

Figure 3. The offline migration approach.
In the offline migration approach, you turn off your old SQL system completely while you build a migration to NoSQL. It’s considered the simplest and safest method as there’s less chance of data loss. This is the data migration workflow:
- Migrate data model
- Migrate function and data access objects
- Extract, transform, load (ETL)
Then, you can start the new NoSQL function, and if you tested everything correctly, you can serve reads and writes from the real application. But there’s no guarantee that the new NoSQL application will work in every case, and most applications can’t afford downtime, which leads us to the second approach.
Approach 2: zero-downtime migration with shadow writes

Figure 4. The zero-downtime migration with shadow writes approach.
To achieve zero downtime, you need to simultaneously run the old and new functions in parallel. Give yourself enough time to test it before switching completely and shutting down the old function. The first two steps of the data migration workflow for this approach are the same:
- Migrate data model
- Migrate function and data access objects
But now you can start using the new function as if we’ve already completed the migration and run shadow-writes. This allows the writes from the real application to reach both the relational database and the NoSQL database.
Because we’re doing shadow writes, we’ll need a proxy to send data to a relational database and the same data will be shadowed to Cassandra. At this point, we’re heavily testing writes and ensuring our tables and our data models are designed correctly.
If you made a mistake during this process, you can always switch back to the relational database because you have replica data there. Although we’re using Cassandra as an example, you can do this with any other NoSQL migration.
The next step is to extract, transform and load historical data to Cassandra. After that, you keep running both databases and make sure the reads work as you expected. Once you’re ready, turn off or replace your old solution with the new one. For a more detailed explanation, check out this video on SQL to NoSQL.
Approach 3: minimal-downtime migration with dual reads

Figure 5. The minimal-downtime migration with dual reads approach.
The interesting thing about this approach is that you’ll do dual-reads, which means running both relational and Cassandra databases at the same time with no intention to turn off the relational one completely. Again, the first two steps are the same:
- Migrate data model
- Migrate function and data access objects
In the third step, you can use your new function to do the writes to Cassandra, but the historical data is still in the relational system. When you do the reads, you need to read both from Cassandra and the relational system, which you’ll need a proxy for. Once you’re ready, you ETL the historical data from a relational database to Cassandra. Then, switch the feature off and use it on Cassandra.
There are certain use cases when this approach is favorable:
- If the historical data in your relational database is not that important and you read it infrequently, there’s no point in moving your data, doing the ETL and spending your resources on storing that data in Cassandra.
- If the historical data uses relational features that are not available in Cassandra or are not easy to implement in your application.
- If you have already prepaid your service cloud SQL database service and you want to keep using it while you have the resources.
Head over to this video for a more in-depth explanation.
Conclusion
Because Astra DB automates the tuning and configuration of Cassandra databases, you can build and deploy cloud-native NoSQL applications in a matter of minutes. Astra DB is free-of-charge up to 80GB storage and 20 million monthly operations; no credit card commitment required. Even beyond this, Astra DB is completely serverless, allowing you to run Cassandra clusters only when needed and lowering your costs significantly.
You can pick and choose the approach that fits the needs of your organization and the features of your applications. But all three approaches in this post have one thing in common: you always need to migrate data model, function, and data.
Migrating data models from SQL to NoSQL is perhaps the most challenging. Join us in Part 2 of the data migration series and conquer the challenge with in-depth examples and hands-on exercises using a Spring PetClinic application, Astra DB and DataStax Bulk (DSBulk).
If you’d like to learn more about Cassandra, check out DataStax Medium and our YouTube channel for plenty of Cassandra-based workshops. You can even become Cassandra-certified on DataStax Academy. Join us at DataStax Community, the stack overflow for Cassandra, if you have specific questions, or chat us up on Discord.
Resources
- Astra DB: Multi-cloud DBaaS built on Apache Cassandra™
- YouTube Tutorial: From SQL to NoSQL
- GitHub: SQL to NoSQL Migration Workshop
- DataStax Bulk Loader for Apache Cassandra
- Part 1: Introduction to Apache Cassandra - the “Lamborghini” of the NoSQL World
- Part 2: Advanced Data Modeling on Apache Cassandra
- Part 3: A Beginner’s Guide to Benchmarking with NoSQLBench
- Part 4: Supercharge your Apache Cassandra Data Model with Storage-Attached Indexing (SAI)
- Migrating from SQL to NoSQL with Spring PetClinic and Apache Cassandra®
- Data Age 2025: the datasphere and data-readiness from edge to core
- DataStax Medium
- DataStax YouTube Channel
- DataStax Academy
- DataStax Community
- DataStax Developers Twitter






