
Welcome to Part 4 of a six-part series on Apache Cassandra®. Here’s what we’ve covered so far:
Part 1: Introduction to Apache Cassandra
Part 2: Advanced Data Modeling on Apache Cassandra
Part 3: Benchmark Your Database with NoSQLBench
This fourth post, based on our “Power up your Apache Cassandra Data Model” YouTube tutorial, will show you how to add flexibility to your Cassandra database model with Storage-Attached Indexing (SAI) features on DataStax Astra DB, a managed Cassandra-as-a-database-service on the cloud.
If you’ve been a long-time user of Cassandra, this will be completely new information that unlocks some things you didn’t think you could even do. If you’re new, we just lowered the bar for application data modeling. All of our workshops are based on the Free Forever tier of Astra DB, so you can upskill in Cassandra for free, forever.
Welcome to the cutting edge of Cassandra!
Indexing in distributed systems
Indexing is the process of associating a search key with the location of a corresponding data record. If you’ve ever worked with a database, you’ve used a primary index where you set up a primary key for a data table. Indexing is done automatically with primary keys, and data lookup is fast and efficient.
But when we go beyond the primary index into non-primary key queries, things start to change. A relational database will do the lookup, but Cassandra returns an error because the data layout in distributed systems is very different. Not only that, but non-primary key queries are unusable at scale, so Cassandra specifically disallows that.
Because a main index organizes data based on a primary key, the table may be organized as a B+ tree. In a B+ tree, leaf nodes store rows, rather than a grid with rows and columns. For both relational and Cassandra databases, truly efficient querying is supported on primary keys.
Secondary indexes help with querying non-primary-key columns, but a secondary index is generally less efficient than a main index. Again, this is true for both relational and Cassandra databases. Since developers still needed to run non-primary key queries, several secondary indexing practices emerged.
Limitations of secondary indexing
To understand secondary index limitations, let’s take a closer look at how they work, in comparison to Cassandra tables and materialized views.
Tables and materialized views are examples of distributed indexing. Based on a partition key, table or view data structure is distributed across all nodes in a cluster. When retrieving data using a partition key, Cassandra knows exactly which replica nodes may contain the result. For example, in a 100-node cluster with the replication factor of 5, a query needs at most 5 replica nodes and 1 coordinator node.
In contrast, secondary indexes are examples of local indexing. A secondary index is represented by many independent data structures, indexing data stored on each node. When retrieving data using only an indexed column, Cassandra has no way to determine which nodes may have necessary data. Therefore, it has to query all nodes in a cluster. For example, given a 100-node cluster with any replication factor, all 100 nodes have to search their local index data structures. This does not scale well, and can get costly.
Therefore, for real-time transactional queries, you should only use a secondary index when a partition key is also known. This makes your query retrieve rows from a known partition based on an indexed column. In this case, Cassandra takes advantage of both distributed and local indexing.
For expensive analytical queries that retrieve a large subset of table rows based on a low-cardinality column, secondary indexes are also beneficial for distributing processing across all nodes in a cluster. These types of queries generally run via Spark-Cassandra Connector, where retrieved data is further processed using Apache Spark™. Note, however, that Apache Solr™-based search indexes perform substantially better than secondary indexes in this use case.
Secondary indexing in Cassandra
Secondary indexes have been around since the beginning of Cassandra to search column data and run arbitrary WHERE clauses. Although it has a very user-friendly syntax, it would reindex all the columns and tables whenever there was a write to the database on Cassandra. This made it very hard for enterprises to manage their databases.
After a while, Apple introduced Storage-Attached Secondary Index (SASI) for tokenized text searching with fast range scans and in-memory indexing. But SASI blew up disk usage with inefficient indexing, and it was difficult for general users to get the hang of it since its syntax was for a specific use-case.
Along came DataStax Enterprise (DSE) Search, integrating the Solr-Lucene combination, which is a powerful search engine and indexing setup for relational or distributed databases. Historically, Lucene is the gold standard for indexing text data. The two-for-one combination allows DSE Search to provide full text searching, efficient indexing and in-memory indexing. This YouTube video gives a full breakdown of different secondary indexes available for Cassandra.
The solution: Storage-Attached Indexes (SAI)
DataStax’s Storage-Attached Indexing (SAI) addresses the shortcomings of secondary indexing practices by providing the most efficient secondary index for Astra DB and Cassandra yet. SAI has the user-friendly syntax used in secondary indexing and in-memory indexing like SASI.
You can use SAI to add column-level indexes to any column and almost any Cassandra data type including text, numeric, and collection types. This functionality enables you to filter queries using CQL equality, range (numeric only), and CONTAINs semantics. SAI provides more functionality compared to Cassandra secondary indexes, is faster at writes compared to any Cassandra or DSE Search index, and uses significantly less disk space. Figure 1 illustrates the density expectations on the disk of SAI, SASI, and Legacy 2i.
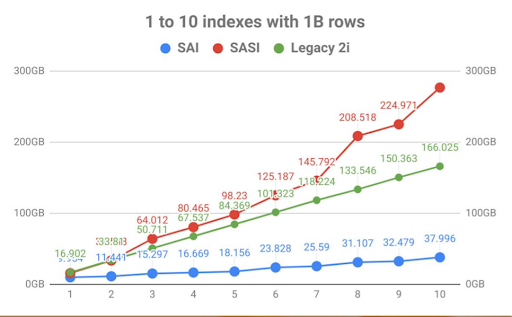
Figure 1. Density expectations on disk.
You can now run powerful queries at scale beyond primary keys on Cassandra just like you would on relational databases. Figure 2 shows examples of Storage-Attached Indexes on Cassandra that you later on create in hands-on exercises.

Figure 2. Examples of Storage-Attached Index on Cassandra.
How does this change your data model?
Storage-Attached Indexing significantly simplifies and speeds up the data modeling process on Cassandra. You can now index columns before denormalization for your new data models — just start with a single table and build indexes from there.
Cassandra performs best when the data model is denormalized. But for those of us who come from the relational world, we are used to running flexible queries on a relational database. With Storage-Attached Indexing, you add more flexibility to your Cassandra data model, taking the mental load off denormalization and decreasing the amounts of tables that you have to deal with.
However, if you have tight SLA requirements that call for your response times to be within single digit milliseconds, you’ll still want to denormalize your database. Optimizing for denormalization is optimizing for performance, like optimizing for a Porsche or Ferrari. We give a more comprehensive breakdown of the denormalization and data modeling process here, or read through our documentation and FAQs on SAI.
DataStax is also actively incorporating SAI with Cassandra. Reach out to us at dev@cassandra.apache.org if you’d like to get updated news on this exciting integration.
How to get started with SAI
Let’s go ahead and set up Astra DB to create a fully-realized Cassandra database and query outside of primary keys through SAI. Follow the step-by-step instructions in this video and GitHub to create and configure your Astra database.
Astra DB, built on the best distribution of Cassandra, provides the ability to develop and deploy data-driven applications with a cloud-native service, without the hassles of database and infrastructure administration. By automating tuning and configuration, Astra DB radically simplifies database operations.
Figure 3: Datastax Astra DB Benefits.
Next, simulate a use case of a client data model that a dentist might use on Cassandra. Here’s a breakdown of the steps:
- Navigate to the CQL Console on your Astra DB and login to the database.
- Describe all the keyspaces in your database.
- Create a “clients” table and insert some data.
- Verify that data exists.
- Create indexes on 3 fields–first name, last name, and birthday.
- Execute queries using our indexes.
By this stage, you would have queried against a combination of string and date fields using exact matches, multiple string cases, and date ranges. By adding an index on three fields we significantly expanded the flexibility of our data model. Thinking ahead, let’s add another index to support a new data model requirement for finding clients based on their next appointment.
Hands-on Exercise: How to extend your query capabilities with an IoT Sensor Data Model
Afterwards, you’re ready for an actual IoT use case. In this exercise, you’ll help an organization supercharge their Cassandra data model and make it simple and easy to query beyond primary keys. Watch this video for instructions and visit GitHub for the codes. Here are the steps:
- Navigate to the Studio console on your Astra DB and import a pre-conditioned Studio Notebook.
- Go to Section 3. IoT sensor data model use case to continue on.
Conclusion
We hope that you’ve gained comprehensive knowledge of Storage-Attached Indexing and how it superpowers the efficiency of Cassandra data models. If you’re on the administrative or developer path and looking to learn more about Cassandra, go to DataStax for Developers for more hands-on workshops on Cassandra and embedded exercises–all for free.
If you want to get into the fundamentals of Cassandra and earn a certificate, check out DataStax Academy. Lastly, don’t forget to read Part 1, Part 2, and Part 3 of our Cassandra series here on the DataStax blog!
Check out our YouTube channel for tutorials and DataStax Developers on Twitter for the latest news about our developer community.
Resources
- Astra DB: Multi-cloud DBaaS built on Apache Cassandra
- Indexing in Cassandra with Storage Attached Indexes (SAI)
- YouTube Tutorial: Power up your Apache Cassandra® Data Model
- GitHub: Storage-Attached Indexes Workshop
- What is SAI?
- Frequently asked questions on SAI
- DataStax Enterprise Search
- DataStax Enterprise Databases
- DataStax for Developers Cassandra Workshops and Certifications
- DataStax Katacoda Cassandra Scenarios
- DataStax Academy for Developers
- DataStax Community
- DataStax Medium
- DataStax YouTube Channel
- DataStax Developers on Twitter
- Part 1: Introduction to Apache Cassandra - the “Lamborghini” of the NoSQL World
- Part 2: Advanced Data Modeling on Apache Cassandra
- Part 3: A Beginner’s Guide to Benchmarking with NoSQLBench




