

Knowledge graphs enable the linking of related content in a way that complements vector similarity. In much the same way that hyperlinks allow connecting one website with related information, edges in the graph enable connecting content with other content that’s relevant but not necessarily similar. Often, this provides a more complete context for the generative AI application to reference, leading to more complete answers. Instead of having 10 near copies of the most relevant information, it’s better to have one copy of that and nine pieces of related information providing more depth and breadth on the topic.
We recently introduced content-centric knowledge graphs as a better fit for generative AI and graph retrieval-augmented generation (RAG). Since then, we’ve contributed the GraphVectorStore to LangChain and introduced a variety of techniques for inferring links between content, including explicit links in the HTML, common keywords using Keybert, named-entity extraction using GLiNER and the hierarchy of documents and headings.
Some of these techniques lead to highly-connected knowledge graphs For instance, linking nodes with common keywords will create highly-connected clusters of chunks when applied to documents about the same topics. In the worst case, if every node has the same five keywords, then we create `5 * n * (n - 1)` edges between the nodes. Because the edges are created as data is loaded, this results in the time spent to load nodes increasing quadratically –– each new node has to link to all past nodes!
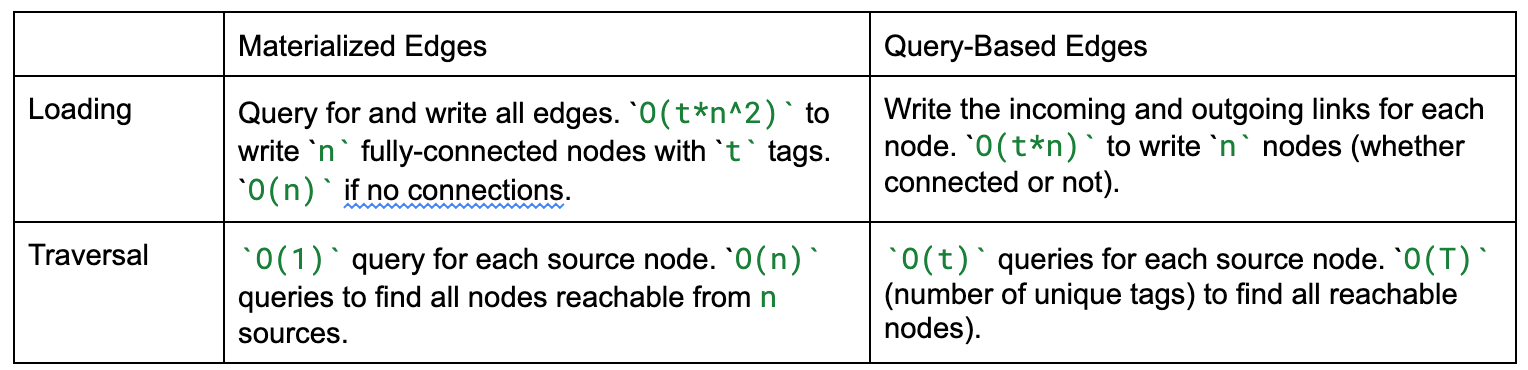
Here, we’ll discuss how we changed the data model to change the complexity class of adding nodes while simultaneously enabling faster traversals. The key change was to store the outgoing and incoming links, rather than materializing the edges. In the keyword example, this lets us persist 5 incoming and outgoing links rather than `5 * (n - 1)` edges, ensuring things don’t degrade as new nodes are added. This requires changes to the traversal to discover the edges at query time rather than when loading nodes. As we’ll see, there are ways to take advantage of that for even faster traversals.
Content-centric knowledge graphs
Content-centric knowledge graphs are knowledge graphs where the nodes represent content – text passages, images and tables, for example. These are particularly well-suited to capturing multimodal information and are much easier to construct than more detailed entity-centric knowledge graphs. The relationships between content – links between passages, images that are referenced by a passage – enable retrieving a more complete context for the large language model (LLM).
Using content as the nodes aligns well with the GenAI ecosystem – a LangChain Document becomes a node. We’ve talked about a variety of ways to introduce edges between those nodes: explicit links in the HTML, common keywords and cross-references, for example. The ability to extract links between documents is important to constructing these knowledge graphs. Depending on how dense the links between nodes are, the original implementation with materialized edges runs into scaling problems.
Links and edges
To increase the compatibility of the content-centric knowledge graphs, we wanted to describe the edges without needing anything more than the metadata on each Document. Rather than describing the edges specifically (this would be impossible, as it relates two different documents), we instead use a concept of “links.” Each document defines zero or more links that connect to corresponding links on other documents.
A node with an outgoing link has an edge to every node with a matching incoming link.
In the example below, we see three nodes. All three are linked together with a common keyword, “foo”. Node 2 is the only node with the keyword “bar,” so it has no edges for that kind/tag. Node 1 has an outgoing link to “bar,” and node 3 has an incoming link, so they are connected with a directed edge.
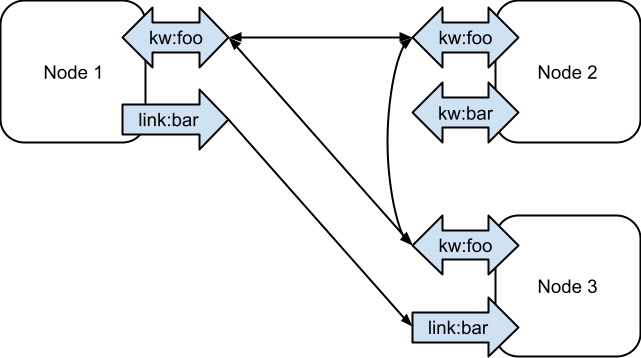
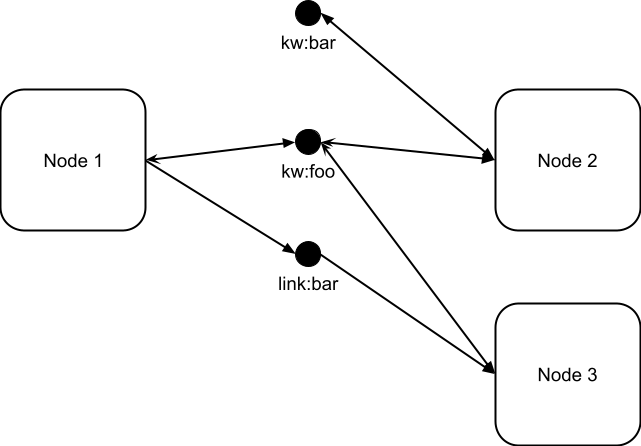
Similar to the way a hypergraph can be represented as a bipartite graph, the above can be visualized as a graph where edges between nodes pass through a different kind of node representing the tag. In this case, an outgoing link is an edge from a node to the tag and an incoming link is an edge from a tag to the node. An edge between nodes in the original graph is the same as a length 2 path between nodes passing through a tag-node in this bipartite graph.
Problem: Common keywords and highly connected graphs
Keywords are a double-edged sword. It can be useful to link nodes with shared keywords together, to enable retrieving information that expands on specific topics from a node. However, when there’s a high amount of overlap in keywords, it quickly degenerates into a fully-connected graph, with edges between all pairs of nodes. Using techniques like TF-IDF (term frequency-inverse document frequency) to select keywords that are more unique across documents can help, but ideally, even when there’s a high degree of connectivity, the performance of the knowledge graph doesn’t degrade.
Solution: Avoid materializing edges
Rather than linking nodes when they are added by explicitly materializing edges, we can query for the connections while traversing the graph.
Loading
The main change here is that rather than storing edges keyed by source, we now store incoming tags keyed by tag. This allows us to ask for all targets of an edge from a given node.
Traversal
Changing to query for connections during traversal does mean that finding the targets for a given source node requires a separate query for each outgoing tag. However, this doesn’t degrade performance for a variety of reasons:
-
The implementation is able to query for linked nodes for each tag in parallel. Using a highly scalable database like Astra DB / Apache Cassandra makes the use of concurrency a viable technique.
-
We denormalize the target text embedding, so that each query can be for the top target nodes by similarity to the query. Rather than fetching all the nodes, this allows us to limit the query to the best nodes to consider for each outgoing tag.
-
We can remember the outgoing tags that we’ve already handled. In the case of highly connected (common) tags, once we’ve retrieved the set of nodes with an incoming link for a given keyword, we don’t need to do that again – even though there are other edges to that node, the result is the same (reaching that target). This enables the traversal to cut off much earlier than if it had to traverse edges. Essentially, we take advantage of the bipartite graph, and remember both visited content nodes and visited tag nodes.
In fact as you’ll see in the benchmark, we find that traversing the tags in this way is actually faster than traversing the edges. Building for inter-connected content on top of a general purpose database lets us optimize the schema and query patterns for retrieval. In this case, it allows us to consider each tag connecting nodes once during the traversal (the set of reached nodes doesn't change), while a conventional graph would need to consider every edge between nodes.
Use Case: Keyword links from a PDF
To demonstrate the use of keywords, we show how to load a PDF, split it into chunks, and extract keywords for each chunk using Keybert.
from langchain_openai import OpenAIEmbeddings
import cassio
from langchain_community.graph_vectorstores.cassandra import (
CassandraGraphVectorStore,
)
from langchain_community.graph_vectorstores.extractors import (
LinkExtractorTransformer,
KeybertLinkExtractor,
)
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Initialize AstraDB / Cassandra connections.
cassio.init(auto=True)
# Create a GraphVectorStore, combining Vector nodes and Graph edges.
knowledge_store = CassandraGraphVectorStore(OpenAIEmbeddings())
# Load and split content as normal.
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1024,
chunk_overlap=64,
length_function=len,
is_separator_regex=False,
)
loader = PyPDFLoader("Tourbook.pdf")
pages = loader.load_and_split(text_splitter)
# Create a document transformer extracting keywords.
transformer = LinkExtractorTransformer([
KeybertLinkExtractor(extract_keywords_kwargs={
"stop_words": "english",
}),
])
# Apply the document transformer.
pages = transformer.transform_documents(pages)
# Store the pages in the knowledge store.
knowledge_store.add_documents(pages)Benchmark results
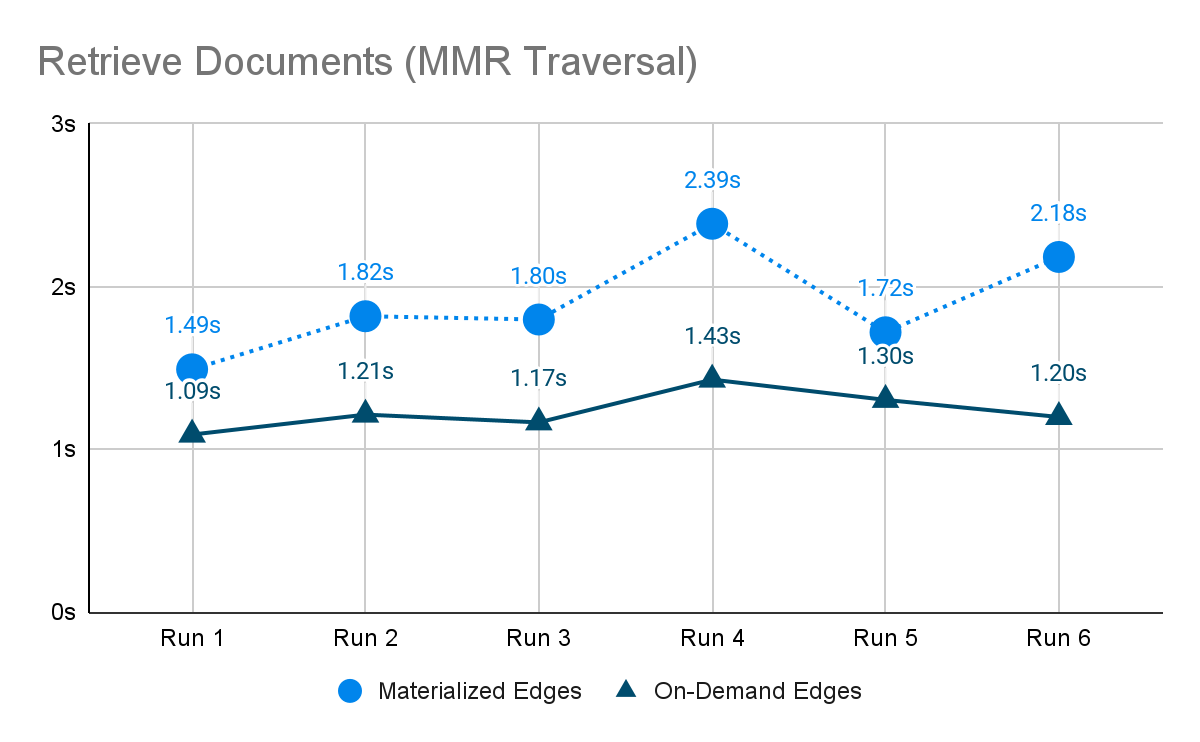
A PDF document about travel to India was split into 136 chunks, and loaded into a content-centric knowledge graph six times. Each time it is loaded it creates 136 new chunks. With the old approach (materialized edges), we see the time to load the document start off high, and increase roughly linearly; every new document has to link against all the old documents, which increase over time. So the total time to load all of the documents is exponential. With the new approach (on-demand edges), the time is constant and generally much lower since edges aren’t being created.
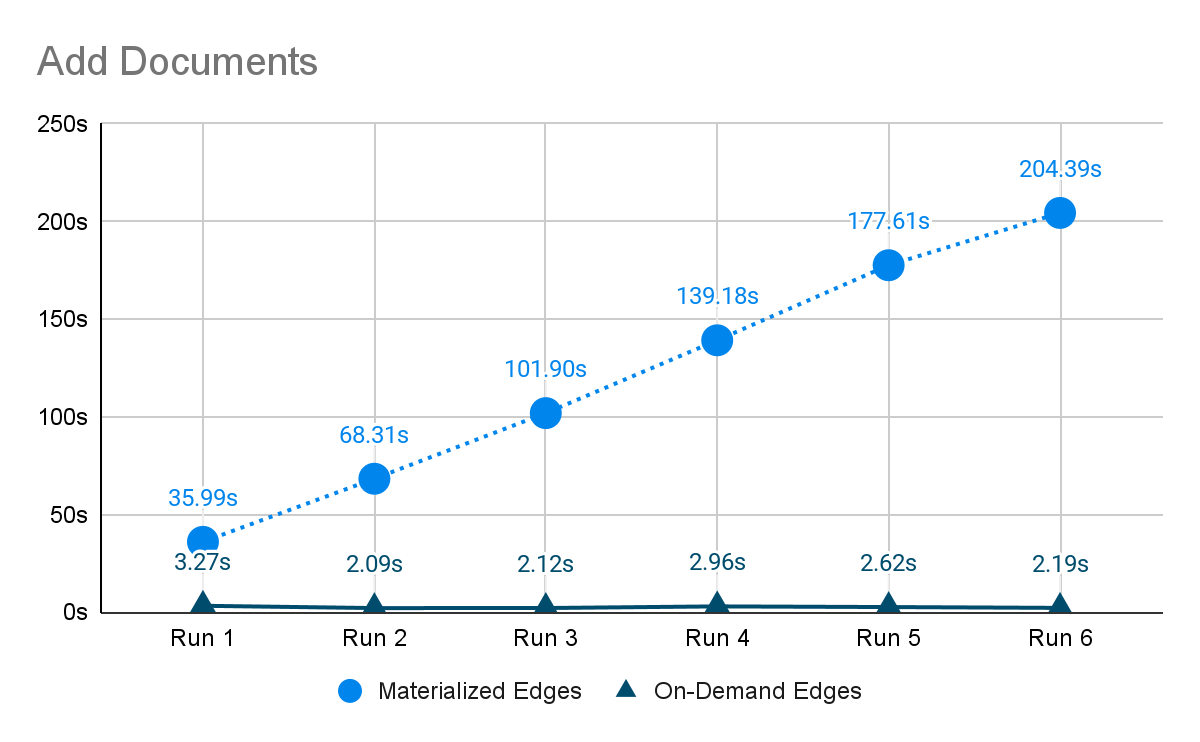 We also see that in both cases the time spent traversing the graph to retrieve documents is about the same – relatively constant.
We also see that in both cases the time spent traversing the graph to retrieve documents is about the same – relatively constant.
Try it out!
Content-centric knowledge graphs are as fast and easy to populate as vector stores. By storing information about what each `Document` links to, it’s possible to scalably and efficiently store graphs with arbitrarily high connectivity. Traversal guided by maximum-marginal relevance allows traversing the graph to retrieve the most relevant and diverse information related to the query (and related information linked to that).
To experience the benefits of these advancements, try out the latest improvements in langchain-core 0.2.23 and langchain-community 0.2.10. We invite you to integrate content-centric knowledge graphs into your projects using LangChain and explore further enhancements in connecting and retrieving content. Share your feedback and join us in refining these tools to push the boundaries of what's possible with knowledge graphs in AI.






