

Machine learning: the secret behind the neural networks that Netflix and Spotify use to offer recommendations and the underlying technology behind Siri’s voice recognition. It’s changing the world at a rate none of us could have expected. No longer a buzzword, it’s a powerful technology that developers and IT leaders need to begin to understand now to be better prepared for the future.
In this post, you’ll discover the goals and approaches of machine learning, and why Apache Cassandra® is the perfect tool for executing large datasets and the tech stack of choice for companies like Uber, Facebook, and Netflix.
In Part 2 of this series, we’ll give you an overview of how Apache Spark integrates with Cassandra to power machine learning and how to build effective algorithms and solutions. You’ll also write your very own machine learning code using Python, Cassandra, and Spark. Both posts in this series build on a video tutorial we’ve created called “Machine Learning with Apache Cassandra and Apache Spark.”
Why Apache Cassandra for machine learning?
Let’s start with an overview of Cassandra, a distributed, NoSQL database management system built to handle large amounts of data across multiple data centers in the cloud. Unlike relational databases like MySQL or PostgreSQL, Cassandra’s distributed structure provides a simple design, horizontal scaling, and extensive control over availability.
For computers to learn effectively, machine learning needs access to big data sets because “small data” may not be enough to properly train a model. A poorly trained model may be able to execute different algorithms, but it would be less likely to deliver reliably useful outputs to businesses.
Organizations need to use a database to feed information efficiently into machine learning. But not just any database: they need one built to support predictable linear scalability and masterless architecture. Cassandra can handle much more data than a relational database, making it ideal for training machine learning models.
Let’s look at five ways Cassandra supports machine learning:
1. Great scalability
Usually, we scale data horizontally by adding new nodes or vertically by replacing old nodes with a more powerful node. But the more data you store and the more clients you have, vertical scaling becomes very expensive. This is fine when your organization works with a few gigabytes of data. But, when data read and write throughput exceeds terabytes (TB) and starts counting in petabytes, you need a scalable database. Each Cassandra node stores about one TB of data and conducts 3,000 transactions per second, tackling the scale challenge with ease.
With Cassandra, if you need more capacity, you can simply add new nodes. The more nodes you add, the more throughput you have. Thanks to its distributed structure, Cassandra is the only database where you can scale your data linearly and minimize cloud cost, making it the most elastic database on the market.
2. Decentralized data distribution
For machine learning to work correctly, we need to continue feeding data into the database, making decentralized and fault-tolerant databases essential. Because Cassandra is a completely decentralized database, its network is architectured so that every node in the cluster is identical in terms of its responsibilities, while each is responsible for different partitions (data is partitioned into multiple groups).
In Figure 1, we have a Cassandra Datacenter with seven nodes. Let’s say we create a table in which we specify a column that will be the partition key, the column for countries in this case. Even if we have 12 records based on the value of the partition key (shown in red), values are distributed among the nodes around the Datacenter.
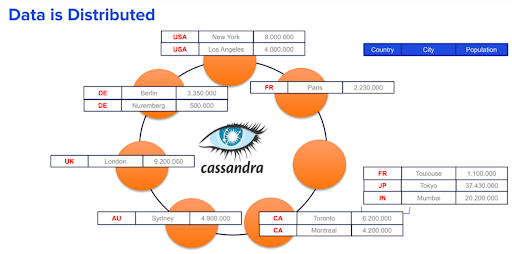
Figure 1. Data distribution on Cassandra.
Cassandra has an internal mechanism to distribute the keys evenly around the cluster. When you hash the partition key, you get a token which is then evenly distributed around our nodes. Each node communicates to each other using a brilliantly named protocol called “gossiping” and grouped in a Datacenter (also commonly referred to as a “ring”). Cassandra is designed this way to handle any amount of data—from megabytes to petabytes—and store it all on a single cluster.
3. Data replication for extreme fault tolerance
Not only data is distributed, but it is also replicated throughout the datacenter. If we set the replication factor to two, it means two copies of each row where each copy is on a different node. The best practice is to set the replication factor to three or an odd number, which we've explained in more detail in our video tutorial.
For some scenarios, you can afford to lose a whole datacenter with no downtime (as long as you have more than one datacenter. However, Cassandra automatically replicates data to multiple nodes, which makes replacing nodes possible without taking the entire database offline. So, even if you lose any of the nodes from the datacenter, it won’t be a big deal.
Think about it: if, for whatever reason, your database goes down, you don’t have to wake up in the middle of the night and deal with it or with angry clients. You can fully recover it, ensuring 24/7/365 uptime. And for most scenarios, this recovery is fully automated, so you don’t have to initiate it manually.
4. Cloud-native and masterless
A cloud-native database like Cassandra is essential for companies like Uber, Apple, and Netflix with a global user base. When you take Uber in Paris to the airport and arrive on the other side of the world, you’d want your account to be up-to-date. Cassandra is designed to be a native data center across the world with multiple data centers globally to read and write from anywhere.
As we explained in our machine learning tutorial, since there is no master, Cassandra is active everywhere, ensuring high performance for modern applications. Every node can handle read and write requests to replicate data seamlessly and effortlessly whether on-premises or on hybrid/multi-cloud.
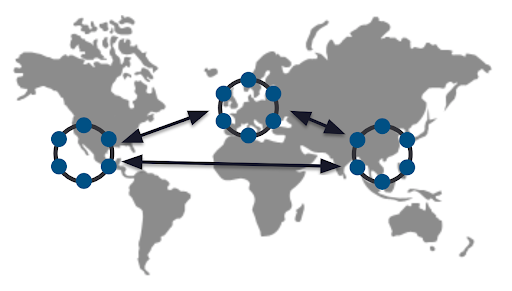
Figure 2. Cassandra has multiple data centers to read and write from anywhere.
5. Balancing availability and performance for data accuracy
When implementing machine learning, a database needs to implement the best-read and write best practices for minimal data inconsistency. The famous “CAP” theorem states that a database can’t simultaneously guarantee consistency, availability, and partition tolerance.
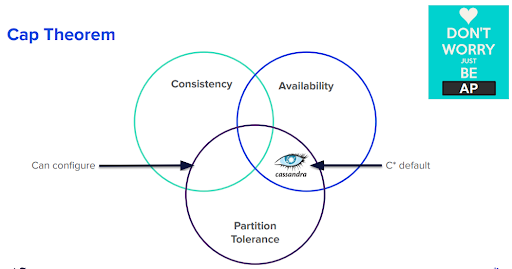
Figure 3. CAP theorem illustrated.
Partition tolerance refers to the idea that a database can continue to run even if network connections between groups of nodes are down or congested. Since network failures are a fact of life, we pretty much need partition tolerance. So, from a practical standpoint, distributed databases tend to be either “CP” (which prioritizes consistency over availability) or “AP” (which prioritizes availability over consistency).
Cassandra is usually described as an “AP” system, meaning it errs on the side of ensuring data availability even if this means sacrificing consistency. However, Cassandra seeks to satisfy all three requirements simultaneously and can be configured to behave much like a “CP” database. This means that Cassandra offers the best possible performance for machine learning, which requires both high data availability and consistency.
In short, Cassandra offers a high-availability and high-performance database built with masterless architecture that’s capable of supporting high-velocity machine learning algorithms with no single point of failure.
Applying machine learning in the real world
There are plenty of articles on what machine learning is and how it works, but they are usually full of jargon. A simpler definition is that machine learning is a way to process raw data using algorithms to make better decisions. However, that definition doesn’t really explain the “how” of machine learning. Let’s instead look at the goals and processes/workflows involved because the practical approach is really the best way to develop a good understanding of the topic.
Many modern companies across many industries already use machine learning for a variety of things, including:
- Forecasts. From the appliance point of view, forecasting is the most difficult use case of machine learning. This includes forecasting for prices, ratings, or weather. For example, you can use machine learning algorithms to determine what the best price for a product would be to maximize income.
- Aberration detection. Very often, machine learning is used for aberration detection such as detecting an incoming fraud on a banking system or locating a disease.
- Classification. Classification is one of the most widely applied uses of machine learning. This includes facial recognition, categorization, or spam detection.
- Recommendation. Recommender systems in machine learning algorithms provide relevant suggestions to users such as YouTube videos, blog posts, and e-commerce websites.
- Navigation. Machine learning algorithms can also be used for navigational systems like global positioning systems (GPS).
For more detailed use cases, check out our YouTube video tutorial.
The process of machine learning
So how does machine learning work exactly? The learning workflow of machine learning is as follows:
- Question. Depending on the situation, we have different kinds of data, and we choose the question that we are trying to answer.
- Algorithm selection. Then, we choose a machine learning algorithm that we want to use.
- Data preparation. Raw data may be too big or unclean to be processed. We prepare the raw data with features and labels so that the algorithm can understand the data.
- Data split. Next, we split data into three different sets over multiple approaches — training, tuning, and testing.
- Training. The training set is used to train algorithms.
- Tuning. The validating set is used to tune models such as adjusting the settings. Note that training and tuning are often an iterative process performed repeatedly before progressing to testing.
- Testing. The testing set is used to estimate whether the model and algorithms work well or not by using metrics.
- Analysis. The final model is delivered and labels are predicted. The model should work very quickly because it has been trained and tested.
- Repeat. This learning workflow is repeated every time in supervised machine learning.
But where does Cassandra fit into all this? As we explained in the first section, algorithms depend on a lot of data, some of which may not be accurate. Cassandra helps with storing big data and improving accuracy.
With its tabular model, Cassandra integrates very easily with Apache Spark, an open-source unified analytics engine for large-scale data processing making data preparation a lot less work. We can also store results in Cassandra in separate tables very quickly without delays. Finally, we can reap the fruits of our labor to improve our decisions based on the steps we executed. All of this is explained in more detail in our YouTube video tutorial.
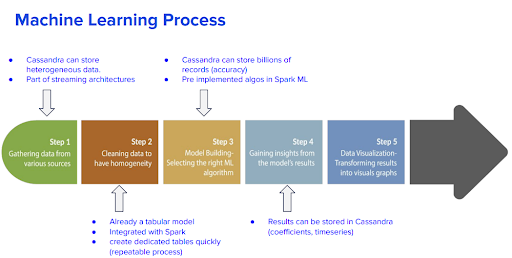
Figure 4. Machine learning process with Cassandra.
Explore machine learning with Cassandra on GitHub
If you want to learn more about how to use Cassandra for machine learning, you can watch our video tutorial or access our Jupyter notebooks in GitHub directly to jump into the hands-on exercises below:
Our goal with this post is to provide you with a basic understanding of how Cassandra is ideally suited for machine learning. But, successful machine learning projects based on strong technologies like Cassandra also need a powerful analytics engine like Spark, which easily integrates with both Cassandra and DataStax Enterprise (DSE). This is a topic we will discuss in-depth in Part 2 of this post.
When you go through the tutorial, you’ll get a deeper dive into machine learning with Cassandra and, combined with the hands-on exercises, you will:
- Learn the basics of working with Apache Cassandra and Apache Spark.
- Discover what machine learning is and its goals and approaches.
- Understand how to build effective machine learning algorithms and solutions.
- Write your very own machine learning code using Python, Cassandra, and Spark.
In Part 2 of this series, you'll learn more about using Spark with Cassandra to simplify data preparation and processing for machine learning.
Explore more tutorials on our DataStax Developers YouTube channel and subscribe to our event alert to get notified about new developer workshops. And, follow DataStax on Medium to get exclusive posts on all things data: Cassandra, streaming, Kubernetes, and more!
Resources
- YouTube Tutorial: Machine Learning with Apache Cassandra and Apache Spark
- GitHub Tutorial: Machine Learning with Apache Spark & Cassandra
- Distributed Database Things to Know: Cassandra Datacenter & Racks
- CAP Theorem
- DataStax Academy
- DataStax Certification
- DataStax Luna
- Astra DB
- DataStax Community
- DataStax Labs
- KillrVideo Reference Application
%20%7C%20DataStax&_biz_n=0&rnd=807206&cdn_o=a&_biz_z=1743406209509)
%20%7C%20DataStax&rnd=208360&cdn_o=a&_biz_z=1743406209512)
