

CQL has been tagged production ready in Cassandra 1.2, it came along with the CQL Native Protocol, a client protocol designed as a replacement for Thrift which was traditionally used. Since then, several new drivers for Java, C# and Python have been released that together with Cassandra 1.2 dramatically simplified the way developers and ops work with Cassandra.
Despite this great progress, several limitations remain in this environment when a developer tries to batch prepared statements, to use blobs in non-prepared statements or to page over very large results. Cassandra 2.0 brings some improvements for these use cases and this article enumerate these improvements.
Batching Prepared Statements
As the new data model introduced with CQL3 breaks wide rows into several CQL rows, it's common for applications to require to batch multiple insert statements. Naturally, CQL comes with a BEGIN BATCH...APPLY BATCH statement that makes it possible to group together several inserts, so that a developer can build a string of such a batch request and execute it. The problem actually comes when one wants to use a Prepared Statement for this batch. Prepared Statements are usually useful for queries that frequently executed in an application with different values as they reduce the network traffic and the overall processing time on both clients and servers by making it possible to send only the values along with the identifier of the Prepared Statement to the server.
What is possible with Cassandra 1.2 is to create a Prepare Statement of a statically defined BATCH statement which in Java looks like:
PreparedStatement ps = session.prepare( "BEGIN BATCH" + " INSERT INTO messages (user_id, msg_id, title, body) VALUES (?, ?, ?, ?);" + " INSERT INTO messages (user_id, msg_id, title, body) VALUES (?, ?, ?, ?);" + " INSERT INTO messages (user_id, msg_id, title, body) VALUES (?, ?, ?, ?);" + "APPLY BATCH" ); session.execute(ps.bind(uid, mid1, title1, body1, uid, mid2, title2, body2, uid, mid3, title3, body3));
This is not satisfying in many situations as we need to know upfront how many rows we want to insert. Also it's not possible to use BoundStatement#setXXX(String, Object) methods which allows us to bind each variable by column name because of the duplicates found in this batch.
Alternatively, we could send insert statements as several requests. This can be done efficiently using Prepared Statements, Asynchronous Requests and Token Aware Load Balancing that can be found in the three DataStax drivers. Doing so will avoid creating any hotspot in the cluster by spreading the load evenly across the cluster. Additionally note that as the CQL Native Protocol supports request pipelining, statements sent right after each other to the same node on the same connection will look pretty much like a batch on the wire. Unfortunately a drawback of this solution is that we won't have the atomicity and isolation guarantees that come with a batch. Also, if we have many rows to insert or update, we may want to use a batch anyway in order to improve overall performance by saving some request processing overhead.
Fortunately, starting from Cassandra 2.0 it's possible to batch Prepared Statements. As this is made possible through an updated version of the CQL Native Protocol, it's necessary to use an up to date driver; a first beta version of the Java Driver for Cassandra 2.0 is now available. C# and then Python will follow. So starting from version 2.0 of the Java Driver we're able to do:
PreparedStatement ps = session.prepare("INSERT INTO messages (user_id, msg_id, title, body) VALUES (?, ?, ?, ?)");
BatchStatement batch = new BatchStatement();
batch.add(ps.bind(uid, mid1, title1, body1));
batch.add(ps.bind(uid, mid2, title2, body2));
batch.add(ps.bind(uid, mid3, title3, body3));
session.execute(batch);
The code above will execute these 3 Prepared Statements as a batch. Note that we're allowed to provide any kind of statements to a batch, either prepared or not.
Parameterized Statements
Sometime you're not able to prepare a statement upfront, this can be the case for instance when you dynamically generate a query string or when you create a tool or a framework. Or maybe you don't want to prepare it upfront because it will be used only once and preparing it would cost you an extra round trip. In this situation the values that you want to write in Cassandra need to be inlined in the CQL string. In this situation using a regular (unprepared) statement is more appropriate. But that means that all the data you send will need to be serialized in the CQL String, which is not efficient if these data tend to be large.
Cassandra 2.0 introduces Parameterized Statements, which are regular CQL string statements that can accept question mark markers and parameters just like Prepared Statements. In practice in the Java Driver, it will be possible to quickly create and configure such queries using two new methods on the Session class: execute(String query, Object... values) and executeAsync(String query, Object... values). Say that we want to insert an image, including its bytes and its metadata in a table, that could be done the following way:
session.execute( "INSERT INTO images (image_id, title, bytes) VALUES (?, ?, ?)", imageId, imageTitle, imageBytes );
Automatic Paging
A common issue in Cassandra, and not just with CQL, is that the developer has to carefully limit the amount of results that are returned to avoid over using the memory of both clients and servers. In the worst case, this can lead to an OutOfMemory error. This constraint can be painful with large scale applications where developers need to carefully verify and test each query. The recommended workaround is to manually page over all the results that need to be retrieved. If we recall our first example with the messages table, and imagine we want to retrieve the list of messages for user_id = 101, we can manually page over the results using these two queries:
SELECT * FROM messages WHERE user_id = 101 LIMIT 1000; SELECT * FROM messages WHERE user_id = 101 AND msg_id > [Last message ID received] LIMIT 1000;
Where the second query is used once some results have been received. In the case we need to iterate over an entire table, we'll have to use the token() function are partition key aren't ordered across the cluster, but token of partition key are. So the two previous queries become:
SELECT * FROM images LIMIT 100; SELECT * FROM images WHERE token(image_id) > token([Last image ID received]) LIMIT 100;
Clearly this is not very convenient for developers and add some unnecessary complexity in the client code. Automatic paging introduced in Cassandra 2.0 fixes this situation. In practice automatic paging allows the developer to iterate on an entire ResultSet without having to care about its size: some extra rows are fetched as the client code iterate over the results while the old ones are dropped. The amount of rows that must be retrieved can be parameterized at query time. In the Java Driver this will looks like:
Statement stmt = new SimpleStatement("SELECT * FROM images");
stmt.setFetchSize(100);
ResultSet rs = session.execute(stmt);
// Iterate over the ResultSet here
It's worth looking under the hood here as the way Automatic Paging is implemented enables transparent failover between page responses. This is possible thanks to a paging state that is returned along with each result page that allows the client to request any node for the next page using any load balancing and failover strategy. The following diagrams illustrate this mechanism:
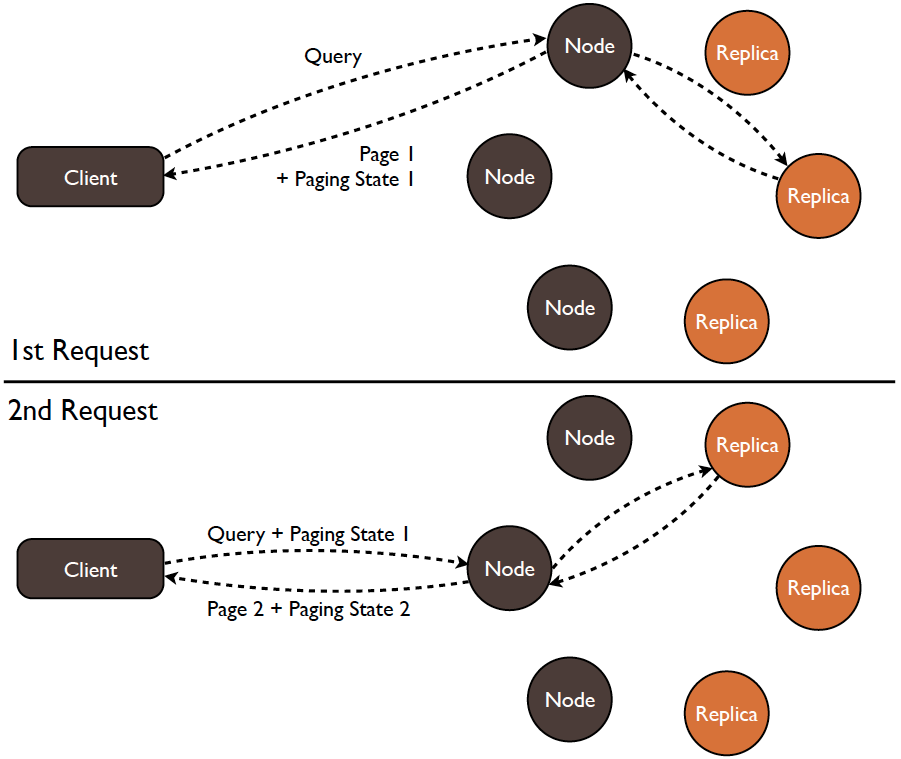
While it's possible to disable automatic paging (in Java this will be done by setting fetchSize to Integer.MAX_VALUE), a developer will typically want to keep it enabled in most situation as it will be a good way to shield an application against accidentally large result sets. For use cases where large results are actually expected, finding the right trade off for the fetchSize setting will be important from a performance perspective: while it's good to keep it to a reasonable size to keep a descent memory footprint, a too small value would lead to too much round trips.
Leaders like Barracuda and Temporal manage Apache Cassandra® with Astra DB. You can too.
Create a ClusterBatching Prepared Statements
Parameterized Statements
Automatic Paging
More Company
View All
Shaping the Wild in Las Vegas: An AWS re:Invent Recap

Announcing 12 Days of Codemas: The DataStax Holiday Giveaway!

London Called. RAG++, The AI Event, Answered!
