

Introduction
Today, we are very excited to unveil some of the most critical performance enhancements we’ve ever made to DataStax Enterprise (DSE). Enterprise workloads are becoming more and more demanding each day, so we took the opportunity to channel the amazing engineering talent at DataStax to re-architect how we take advantage of compute, memory, and storage. It’s not just about speed, either; we’ve made DSE more efficient and resilient to meet the most demanding workloads.
We’ve named our new suite of performance optimizations, utilities, and tools “DataStax Advanced Performance”. The best part? You just need to upgrade to enjoy these out-of-the-box benefits, which include:
- New thread-per-core and asynchronous architecture, which results in double the read/write performance of open source Apache Cassandra®
- Storage engine optimizations that literally slice read/write latencies in open source Cassandra in half
- Faster analytics that can deliver up to 3x query speed-ups over open source Apache Spark™
- DataStax Bulk Loader, which load and unloads data up to 4x faster than current Cassandra load tools
Thread-Per-Core and Asynchronous Architecture
Apache Cassandra uses a traditional, staged, event-driven architecture (SEDA). With the SEDA architecture, Cassandra assigns thread pools to events or tasks and connects them via a message service. This architecture also uses multiple threads per task, meaning that threads need to be coordinated. Additionally, events in this architecture are synchronous, which can cause contention and slowdowns. Because of this, adding CPU cores eventually sees diminishing returns.
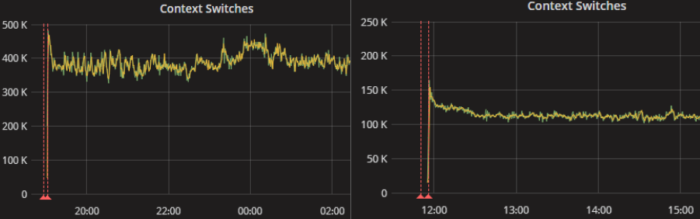
DSE 5.1 left, DSE 6 right - With the traditional SEDA architecture, we see much more context switching which is expensive and degrades performance.
DSE 6 has a coordination-free design, a thread-per-core architecture which yields incredible performance gains. The whole data layer across DSE, including search, analytics, and graph, benefits from this new architectural change.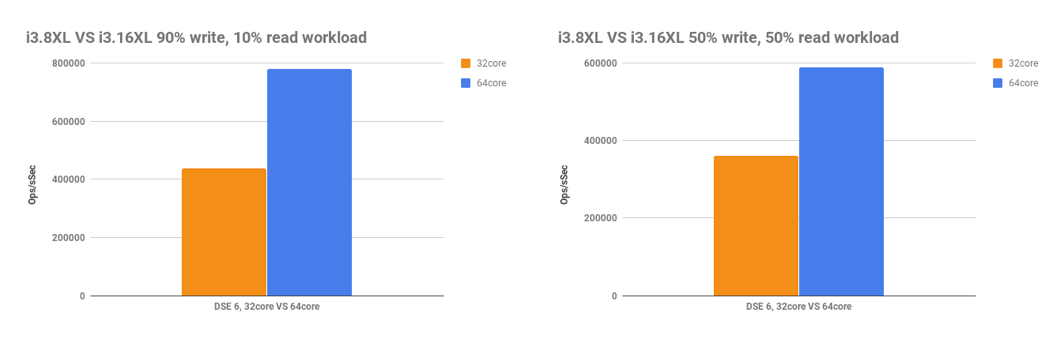
cassandra-stress, 5 nodes, RF=3, CL=QUORUM, 500GB density
Each node in a cluster owns part of the token range; that’s not new. What’s new is that a respective node’s token range is divided evenly among CPU threads: one per CPU core to be exact. A respective thread is now responsible for incoming writes for the part of the token range it owns, and any available thread can be used to handle read requests. This means that evenly distributed data in the cluster results in evenly distributed CPU utilization on a server. This architecture also means that very little coordination is needed between threads, which ensures that a CPU core can be used to its fullest capabilities
.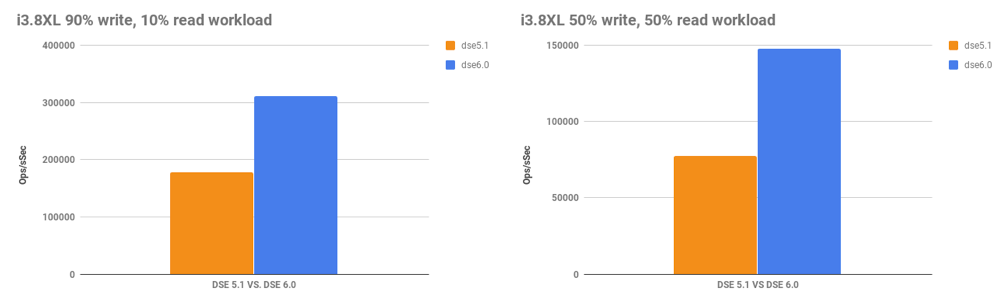
cassandra-stress, 5 nodes, RF=3, CL=One, 500GB density
Since a single thread owns the writes for its respective token range, what about contention? In DSE 6, we’ve moved reads, writes, and other tasks from synchronous operations to asynchronous. This allows us to eliminate thread contention, always keeping threads working. Combined with the thread-per-core architecture, this allows us to scale performance linearly as we scale the number of CPU cores. This is extremely important as multi-socket motherboards and high core-count cloud instances have become the standard.
Storage Engine Optimizations
Besides ingesting and serving data faster with thread-per-core, we've also made improvements to the storage engine that improve latency and optimize compaction, which can also be a bottleneck for write-heavy workloads. In DSE 6, that compaction performance is 22% faster than in DSE 5.1 which is already 2x faster than open source Cassandra. We’re also seeing latency improvements of 2x on reads and writes.
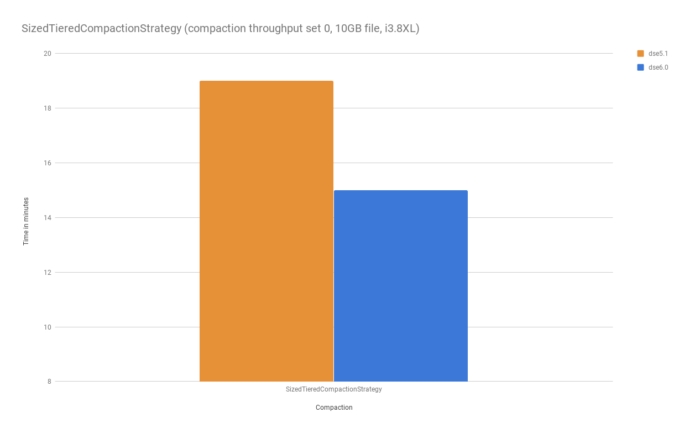
In DSE 5.1, we introduced 2x compaction performance over Apache Cassandra. In DSE 6, compaction is even faster.

40k fixed throughput test, 3 nodes, RF=3, CL=QUORUM
Faster Analytics Scans
Also included in DSE Advanced Performance are improved analytics read performance that is 3x over open source Cassandra and Spark. This was made possible by a feature called Continuous Paging, an optimization designed specifically for DataStax analytics queries that scan a large portion of data. We have tested this in a number of scenarios: selecting all columns or some columns, with or without a clustering-column predicate, and in all scenarios we see a 2.5 to 3.5x performance improvement.

3x analytics read performance over open source Spark and Apache Cassandra.
DataStax Bulk Loader
Also new in DSE 6 is a bulk loader utility that greatly outpaces current Cassandra load/unload utilities. The command line tool handles both standard delimited formats as well as JSON and can load and unload data up to 4x faster than current tools.
Conclusion
We’re extremely excited for our customers to experience the new Advanced Performance capabilities of DSE 6. With a 2x throughput improvement, massive latency improvements, 10% compaction improvement, a 3x analytics improvement, and a crazy-fast bulk loader, we can’t wait to see the kinds of innovation and disruption our customers will continue to make. To download DSE 6 and for more information on DSE Advanced Performance, check out this page.






