

Introduction
DSE Search (Apache Solr based) and DSE Analytics (Apache Spark Based) may seem like they are basically designed for orthogonal use cases. Search optimizes quick generic searches over your Big Data and Analytics optimizes for reading your entire dataset for processing. But there is a sweet spot where Analytics can benefit greatly from the enhanced indexing capabilities from Search. Previously in DSE this synergy could only be accessed from the RDD API but now with DSE 5.1 we bring DSE Search together with DSE Analytics in SparkSQL and DataFrames.
Requirements
DSE Search must be enabled in the target datacenter of the SparkSql or Dataframe request. DSE Analytics must be enabled on host datacenter of the request. Locality is only guaranteed if both Search and Analytics are colocated in the same Datacenter.
Turning on and off the optimizations
In 5.1 this feature is Opt-In and is only useful in certain scenarios which we currently do not automatically detect. To enable these optimizations set the spark.sql.dse.solr.enable_optimization=true as a Spark configuration option. This can be set at the application level by setting the value in
- spark-defaults
- on the command line with --conf
- programatically in the Spark Conf
It can also be set per DataFrame by passing the parameter as an option to your DataFrame
import org.apache.spark.sql.cassandra._
spark.read
.cassandraFormat("ks", "tab")
.option("spark.sql.dse.solr.enable_optimization", "true")
How it Works
When a query is sent to Spark via SparkSql or Dataframes it ends up in an optimization engine called [Catalyst](https://spark-summit.org/2016/events/deep-dive-into-catalyst-apache-spark-20s-optimizer/).This engine reduces the query into a set of standardized operations and predicates. Some of those predicates are presented to the data source (which can be Cassandra). The Datasource is then able to decide whether or not it can handle the predicates presented to it.
When Solr Optimization is enabled DSE adds a special predicate handling class to the Cassandra DataSource provided in the Datastax Spark Cassandra Connector, allowing DSE to transform the Catalyst Predicates into Solr Query clauses.

These compiled Solr clauses are then added to the full table scan done by CassandraTableScanRDD. Once you have enabled Solr optimization these transformations will be done whenever applicable. If a predicate cannot be handled by Solr we push it back up into Spark.
Debugging / Checking whether predicates are applied
The optimizations are all done on the Spark Driver (the JVM running your job). To see optimizations as they are being planned add the following line to the logback-spark file which is used for your driver
<logger name="org.apache.spark.sql.cassandra.SolrPredicateRules" level="DEBUG"/>
logback-spark-shell.xml # dse spark
logback-spark-sql.xml # dse spark-sql
logback-spark.xml # dse spark-submit
This will log the particular operations performed by the DSE added predicate strategy. If you would like to see all of the predicate strategies being applied add
<logger name="org.apache.spark.sql.cassandra" level="DEBUG"/>
as well.
Performance Details
Count Performance
The biggest performance difference for using Solr is for count style queries where every predicate can be handled by DSE Search. In these cases around 100X the performance of the full table scan can be achieved.
This means analytics queries like "SELECT COUNT(*) where Column > 5" can be done in near-real time by automatically routing through DSE Search. (CP in this graph refers to Continuous Paging another DSE Exclusive Analytics Feature)

Filtering Performance
The other major use case has to do with filtering result sets. This comes into play when retrieving a small portion of the total dataset. Search uses point partition key lookups when retrieving records so there is a linear relationship between the number of rows being retrieved and the time it takes to run. Normally Analytics performs full table scans, whose runtimes are independent of the amount the data actually being filtered in Spark. The speed boosts to DSE Analytics with Continuous Paging have set a low tradeoff point between Search doing specific lookups and running a full scan in Spark. This means that unless the dataset is being filtered down to a few percent of the total data size it is better to leave Search Optimization off.
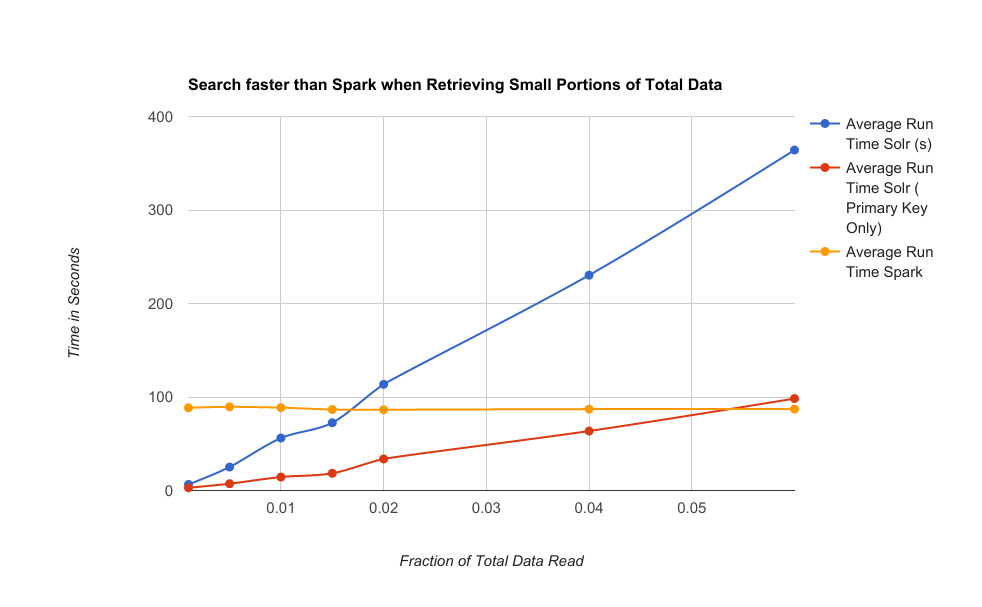
In the above chart, the yellow line (Spark Only) runs at a constant time since it always requires reading the same amount of data (all of it). The Blue and Red lines show that since Search is individually requesting rows, it's duration is dependent on the amount of records retrieved. Since Primary Keys and Normal Columns are stored differently the performance of retrieving primary keys only (Red) is faster than retrieving the whole row (Blue).
For retrieving whole rows (blue), the inflection point is around 1.5 percent of the total data size. If the filter returns less rows than this percentage performance will be better using the Search optimization.
For returning only primary key values (red), the inflection point is around 5 percent of the total data size. Any filters returning less than this percentage will perform better using the Search optimization.
These are some general guidelines and the performance of any system may be different depending on data layout and hardware. .
Caveats
One major caveat to note is that currently the SELECT COUNT(*) query without any predicates currently will only trigger a normal Cassandra pushdown count. This can be forced to use a solr count instead by adding a "IS NOT NULL" filter on a partition key column. We plan on including this as an automatic optimization in the future.
All results returned via DSE Search are subject to the same limitations that DSE Search is bound by. The accuracy of the counts are dependent on the consistency of the Solr core on the replicas that provide the results. Errors at indexing time may persist until manually corrected, especially since the Spark Connector doesn't actually use the same endpoint selection logic DSE Search does.
More Company
View All
Shaping the Wild in Las Vegas: An AWS re:Invent Recap

Announcing 12 Days of Codemas: The DataStax Holiday Giveaway!

London Called. RAG++, The AI Event, Answered!
