

This post will introduce DateTieredCompactionStrategy (DTCS) which is a new compaction strategy that ships with Cassandra 2.0.11, 2.1.1 and later. It aims to keep data written at the same time in the same SSTables to improve performance of time series-like workloads. DTCS was contributed by Björn Hegerfors at Spotify.
Background
Reading data in Cassandra
When a write comes in to Cassandra it writes that data to a commit log and stores it in a Memtable in-memory on the node. Once the memtable is full, it is flushed to an SSTable on disk. Once an SSTable is flushed, it never changes. When a read is executed, data from the Memtable is merged with relevant data from the SSTables on disk. Reducing the amount of reading we need to do from disk is extremely important since that is slow.
A very simplified view of the on-disk format is that we have a bunch of partition keys and each of those partition keys can have many cells. The cells have names and are stored sorted, smallest cell name first, biggest cell name last. For example:
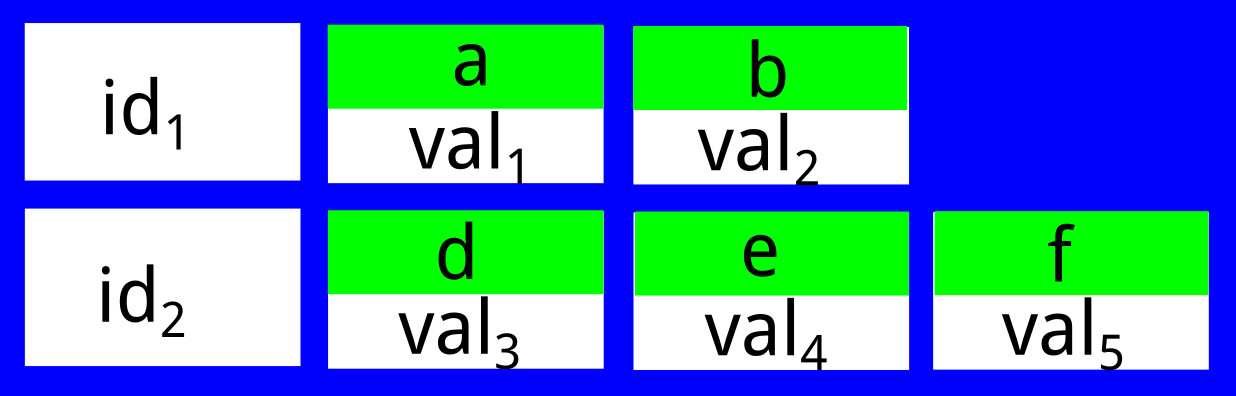
To be able to reduce the number of SSTables Cassandra needs to look at during reads, metadata is stored with each SSTable. For example, it stores the min and max cell names in the SSTable (more details in CASSANDRA-5514). This is then used during reads, for example in the SSTable above, we could avoid reading from the SSTable if we query "all cells bigger than 'j' for partition key 'id1'" since we know that that cell name can not be in the SSTable. We would have to read from it if we queried for "all cells bigger than 'e' for partition key 'id1'" though since the metadata is global for the SSTable (min cell name would be 'a' and max cell name would be 'f' for this SSTable).
For more background on how cells become rows etc, read this blog post.
Compaction
The main purposes of compaction are to reclaim disk space used (removing overwrites and deleted data) and to make sure that we can serve reads from as few SSTables as possible. They are of course related - if you reduce the amount of duplicate data, you are bound to hit fewer SSTables. What we are going to focus on here though is the case when we do no overwrites and only do deletes by TTL, meaning the main purpose of compaction is to make sure we serve reads from as few SSTables as possible and that we drop data that has expired.
Time series data
One common use case for Cassandra is time series data where you might have a table like this:
CREATE TABLE temperature ( weatherstation_id text, event_time timestamp, temperature text, PRIMARY KEY (weatherstation_id,event_time) );
And you insert new temperature readings at various timestamps. This gets laid out on disk in an SSTable like this (again, simplified):

Where event_time always increases (time between 2 different temperature readings will increase), which means that we don't do any overwrites. Note that the global (for all partitions) biggest and smallest cell names in this SSTable will be approximately the same as the min and max timestamps for the data in this SSTable. Also note that it does not matter if we track event times as actual time or something else, as long as they sort after the cells that were inserted earlier (timeuuids or sequence ids for example). We could also put a TTL on the temperature readings, meaning we would only keep the most recent data.
Historically compaction has not cared much about how old the data is when selecting SSTables to compact together - this means that we could mix new and old data in the same SSTables which causes a few problems for time series data:
- We need to look in more SSTables for the most common query types ("give me the last day of data") since all SSTables could contain data from the last day - we can't use the optimization from CASSANDRA-5514 where we exclude SSTables based on the max/min cell names in an SSTable.
- Dropping expired data gets difficult - since columns will expire at different times in the SSTable, we can't use the optimizations from CASSANDRA-5228 where we are able to drop an entire SSTable if all data in the SSTable is expired.
DateTieredCompactionStrategy
The basic idea of DTCS is to group SSTables in windows based on how old the data is in the SSTable. We then only do compaction within these windows to make sure that we don't mix new and old data.
The size of the compaction windows is configurable. The base_time_seconds option sets the size of the initial window and defaults to 1 hour. This means the data that was written in the last hour will be in that first window, and will be compacted with data from the same window. Any reads that want to read data from the latest hour will only have to look at SSTables that were compacted or flushed in that window. The older windows then get larger and larger, and finally we have max_sstable_age_days which is when we don't compact the SSTables anymore.

In this example you can see that the time windows move as time passes. The SSTables are sorted by the age of the oldest data (min timestamp) in them, and the most recent data is on the right. In 1 above, none of the time windows contain 4 SSTables (configurable via min_threshold), meaning no compaction will be started. As time passes, we end up in state 2, where one of the time windows now contains 4 SSTables, and we start a compaction of the SSTables in that window. This creates a new sstable that has the same min/max timestamps as the total min/max timestamps of the compacted SSTables (unless the timestamps were from a tombstone that was dropped). In 3 we see time move again and we end up with 4 SSTables in a window which will be compacted together. This explanation is simplified, for a detailed post on how this works, check out this blog post: https://labs.spotify.com/2014/12/18/date-tiered-compaction/
Dropping expired data
If the data is inserted with TTL, and that TTL is the same for all inserts, all data in an SSTable will expire at approximately the same time since TTL is relative to the timestamp of the data. This makes it possible to optimize the way we drop tombstones - once all data in the SSTable is expired, lets drop the entire SSTable. See CASSANDRA-5228 for more details about how this works.
Out of order writes
Some times you might want to insert old data - for example if you need to backfill some data into the system, this would of course mess up the timestamps in the SSTables. There are a few options to solve this;
- Block all live clients writing data, write the old data, flush SSTables and enable the live clients again.
- Generate SSTables with the old data offline, using CQLSSTableWriter for example and then load those SSTables into the cluster.
Two other things can generate out of order data;
- Hints - hints will send old data to your node, but only data that is max_hint_window_in_ms old - you could align this with your base_time_seconds to make sure you don't get too big time spans in your flushed SSTables.
- Repair - repair can send really old data to your node, but this is also fine, since you run DTCS on all your nodes in the cluster and repair will stream parts of SSTables, all the SSTables streamed will have short time spans, meaning DTCS will put them in the windows and compact them up if needed.
Note that there will almost always be some out of order writes due to clients not having the exact same times, this can generate a small time-overlap between the SSTables. See CASSANDRA-8243 for more details about this.
Switching to DateTieredCompactionStrategy
To change a table to use DTCS, you do this:
ALTER TABLE <table> WITH compaction = {'class': 'DateTieredCompactionStrategy', 'timestamp_resolution':'<resolution>', 'base_time_seconds':'3600', 'max_sstable_age_days':'365'};
The configuration parameters are optional:
- timestamp_resolution: Defines what timestamp resolution you use when inserting data, defaults to 'MICROSECONDS' since that is the default when using CQL, but older clients might use milliseconds for example. You can use any resolution that Java TimeUnit accepts. Note that unless you do mutations with USING TIMESTAMP (or the driver equivalent) you should not change this!
- base_time_seconds: This is the size of the first window, defaults to 3600 seconds (1 hour). The rest of the windows will be min_threshold (default 4) times the size of the previous window.
- max_sstable_age_days: This is the cut-off when SSTables wont be compacted anymore, if they only contain data that is older than this value, they will not be included in compactions. This value should be set to some point where you won't (frequently) read any data. In a monitoring system for example, you might only very rarely read data that is older than one year. This avoids write amplification by not recompacting data that you never read. Defaults to 365 days.
Note that DateTieredCompactionStrategy is new and some things might change in the future, report any issues you find on Cassandra Jira.
For all the implementation details of this compaction strategy, go read CASSANDRA-6602.
It is possible to try out new compaction strategies without switching for the entire cluster - check out this blog post for more information about that.
Summary
DateTieredCompactionStrategy is a compaction strategy specifically written for time series-like data, where data is mostly appended to existing partitions. The problem with leveled- and size-tiered compaction is that they don't care about when the data was written, meaning they mix new and old data, and one characteristic of time series workloads is that you mostly want to read the most recent data. This forces Cassandra to read from many SSTables. Leveled compaction can give great read performance, but with a big write amplification cost - we will need to recompact data a lot. DTCS makes this better by only compacting together SSTables that contain data with timestamps that are close to each other, meaning for a query that requests the most recent data, we can greatly reduce the number of SSTables touched during a read. It also limits write amplification by having an option to stop compacting data that is old and rarely read.
More Technology
View All

How to Create a Local LangChain Vector Database

Apache Cassandra 2024 Wrapped: A Year of Innovation and Growth

