

You’ve created an awesome data model, but can it handle success?
Note: This blog series coincides with the short course Data Model Meets World. This content originally appeared on Jeff's personal blog and is reproduced here by permission.
In this series of articles, I’m responding to a series of questions that I received from a reader of of my book Cassandra: The Definitive Guide, 2nd Edition (O’Reilly), who asked several questions about how the hotel data model presented in the book would work in practice.
Previously we’ve discussed how to navigate relationships between different data types, how to maintain the unique identity of data over time, how to reconcile your data model with your architecture, when to use a multi-model database approach, and how to extend your data models to support new queries.
In this post, we’ll discuss how the data modeling decisions you make both up front and over time affect your ability to maintain high performance as your system scales.
The moving target
Those of you who have built and maintained cloud-scale applications or other large enterprise systems will know that performance is a moving target. We provision hardware based on expected traffic, building in tolerance for peak times. We may even take advantage of auto-scaling technologies to help offload the operational burden of scaling up and down, because we know the load on our system is going to change over time.
If our applications are successful, the load on them grows as we add new users, new features, and new integrations. We carefully instrument and monitor our applications for conformance to key metrics enshrined in service-level agreements (SLAs), because we know that the way our system responds over time is constantly changing. As each new performance challenge arises, we analyze and address it, either by adding capacity (less painful), or reworking key areas (more painful).
In this context of continual optimization for larger and larger scales, the data tier is often a limiting factor, due to factors including I/O throughput, CPU and memory usage. Although we can often gain improvements through in-memory caching technologies, data access speed is often the dominant factor in application performance.
Beyond that, I’ll argue that data modeling is the key driver of data tier performance, whether you’re using Cassandra or not. So if you put those two thoughts together, I’m basically asserting that the data model is the biggest driver of overall application performance, and potentially the biggest factor impacting our ability to scale our applications.
This is certainly not to discount the importance of performance tuning for applications using Cassandra. In fact, there is a whole chapter in the book devoted to Cassandra performance tuning topics including heap size, thread pools, compaction, and so on. And that is just on the Cassandra nodes themselves. The DataStax drivers also offer up a number of options that can be tuned on the application side.
Without question, these aspects of performance tuning are important to the overall performance and scalability of your application as perceived by your end users. But I’ll argue that performance tuning is really about refinement — these knobs that we twist are most likely to help when the basic level of performance is within range of our target SLAs.
Bad data modeling choices, however, can lead to loads on our systems which will render our performance tuning efforts moot. You can’t tune your way around a bad data model.
Anti-patterns show up at scale
We’ve probably all encountered cases where we failed to use a consumer product according to the instructions and then got frustrated when it didn’t work as expected. I’ve definitely seen this happen with Cassandra as well.
There are a number of well known anti-patterns for Cassandra. (See here for a similar list specifically for DataStax Enterprise users). Many of these have to do with deployment and configuration choices, but there are data modeling anti-patterns as well, such as:
- Naive queue implementations
- Distributed joins, and multipartition queries
- Misuse / overuse of indexes
These data modeling anti-patterns are often the most painful because of their impact on the entire system:
- Adding nodes to work around overload issues consumes additional compute resources and operations team attention, driving cost
- Rework to data models can cause application rework and painful data migrations
I’m sure you can come up with some other bad results.
The tricky thing about these anti-patterns is that the problems don’t show up until you have a system that is operating at large scale — ironically, undermining the Cassandra value proposition of elastic scalability that probably attracted you in the first place.
Design for scalability, or pay later
An important reminder that people often don’t take to heart is that up front investment is required to make sure that you have a data model that will perform at scale. We may think that we are familiar with good Cassandra data modeling principles, and how to avoid the anti-patterns, but I’ve seen multiple cases where “clever” data models that looked good on paper, and even worked well with moderate amounts of test data, proceeded to fall over in production. Here are some steps you should take to ensure you are designing models that will scale.
Do the math!
A key step in Cassandra data modeling is to calculate estimates of partition size and data storage size on disk. My colleague @ArtemChebotko has documented formulas to help calculate these estimates, and they are explained in depth in the book. (Note: the size on disk formula has been recently updated for the 3.0 storage engine, as you can read about on StackOverflow.)
In particular, estimating partition size can help you to avoid having partitions that are too wide. You’ll remember that Cassandra stores data according to a primary key composed of partition key and clustering columns, where the partition key determines what nodes will store the data, and the clustering columns uniquely identify separate rows and determine the arrangement of the data within data files (SSTables).

Illustration of a “wide row” in Cassandra
The ability to support wide rows is a powerful feature of Cassandra and supports the fast retrieval of related rows within a partition, but you can run into performance issues with partitions that are too wide. Estimating the number of values that will be stored in a partition can help you to identify where this may be a problem, especially when you estimate for the worst case. See the data modeling chapter from the book for more information on this formula.
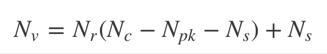
Estimating the number of values in a partition
While estimation is important, you may still encounter cases of wide partitions in production. This often happens as a result of unanticipated errors in other areas. For example, I’m aware of one case where an automated test generating activity for a sample customer account was allowed to run against a production system for longer than intended, resulting in a very wide partition in a table tracking customer activity.
Thankfully, Cassandra does have a configurable log setting to provide warnings when wide partitions are detected, and this warning is something you should keep a lookout for in your logs.
Stress test it!
While estimation is a valuable tool for quickly identifying and discarding problematic designs, there is nothing like testing to see how a data model really performs under load.
The most basic tool for quickly testing out a data model is the cassandra-stress tool that shops with the Apache Cassandra distribution. The tool can be a little hard to understand at first, but there are some great resources available that take you through the process of configuring and running it:
- Blog series from Ben Slater (Instaclustr): Part I, Part II, and Part III
- Cassandra summit talk from Christopher Batey (The Last Pickle)
There is a lot that you can do with cassandra-stress in terms of creating flexible read/write workloads, but there are also some limitations: the tool doesn’t handle UDTs and collections, and only works on a single table at time. In order to test your table designs with cassandra-stress, you’ll need to work around these limitations.
In my opinion, most issues that you encounter with your tables aren’t going to be with UDTs and collections (unless you have very large collections, in which case you should already be rethinking your design). What cassandra-stress is really going to help you find is that first level of semi-obvious scalability issues: wide partitions due to your partition key selection, poorly conceived indexes, and so on.
My basic recommendation is that you use cassandra-stress at least once or twice to get an idea of how it works. You may find that as your data modeling skills mature, you are no longer making those “rookie mistakes” that it helps to uncover.
A similar recommendation is that you examine traces of your queries in order to understand the amount of inter-node interactions going on behind the scenes. This tends to be an eye opener to new Cassandra users.
Application-level load testing
As I imply above, using cassandra-stress is mainly going to help identify obviously poor designs on a single table. While important, this is not going to give you a complete picture of application performance and scalability.
To get that more complete picture, you’re going to need to load test of the application code itself, rather than just Cassandra table access. I’m a big advocate of microservice-style architectures, and one of the big advantages of that architecture style is having data-oriented services that you can address independently that just manage data access. Then you can write tests using tools such as Apache JMeter that apply load on those services, as shown below.
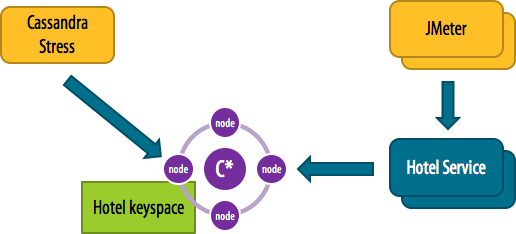
It’s a good idea to stress test your data models — both directly and at the service / application layer
Even if you aren’t using microservices, it’s a good practice to use a pattern such as data access objects (DAOs) in your application to abstract the underlying database and manage any application-level validation of your data that needs to take place.
I strongly recommend having stress tests that can operate at that data layer so that you understand the impact of any validation logic you’ve implemented as well as Cassandra-specific interactions such as usage of lightweight transactions or batches.
Summary
Failing to use techniques like size estimation and load testing puts you at risk of deploying a database design that works for a while, only to encounter problems when the demands on your system increase. At this point the issues are much harder to fix, often requiring application changes and tricky data migrations.
As you get more comfortable with Cassandra data modeling, you’ll be tempted to skip these steps, but I’ve learned the hard way that overconfidence can blind us to flaws that would be easily discovered by doing a few minutes of math or running some simple tests.
As usual, thanks for reading. Next time, in the final post in this series, I’ll summarize everything we’ve talked about in a nice concise package.
More Technology
View All

Streamlining Data Queries with Amazon Q and Cassandra Query Language

