

The more things you have, the harder it is to tell them apart — how the classic problem of identity affects Cassandra data models.
Note: This blog series coincides with the short course Data Model Meets World. This content originally appeared on Jeff's personal blog and is reproduced here by permission.
In the previous article in this series, I shared a series of questions that I received from a reader of of my book Cassandra: The Definitive Guide, 2nd Edition (O’Reilly), who asked several questions about how the hotel data model presented in the book would work in practice. That article focused on the implications of Cassandra’s “query first” modeling approach for navigating relationships between different data types.
In this article, we shift our focus to the issue of identity — how can we make sure that all of our data is uniquely identifiable, both now and in the future?
What is this? — The problem of identity
If you looked the reader questions I shared in the previous article, several of them related to identity:
There might be hundreds of hotels in a large corporation. A sample key like AZ123 would be hard to know by
…POI names have to be unique. How would uniqueness be guaranteed?
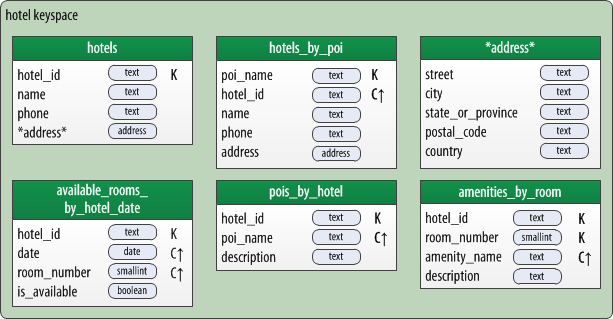
A hotel physical data model using strings as identifiers
My reader makes a key point — an important decision you have to make for each table is how you will determine uniqueness. If you don’t get this correct, you can end up overwriting rows unintentionally. You may already be familiar with the practice of adding additional clustering keys to a table to guarantee uniqueness of each row, as demonstrated by the presence of the hotel_id as a clustering key in the hotels_by_poi table.
These are important considerations, and there is added complexity when our application must integrate with other systems which may have their own ways of identifying data elements.
There always seems to be a tension between our desire for human-readable identifiers and the architectural demand that we guarantee uniqueness. This leaves us with multiple options, each of which have their flaws:
- Human-readable identifiers such as names are an instance of natural keys such as names. They are usually simple to memorize, but are subject to name collisions.
- Codes such as our “AZ123” example are an example of surrogate keys that are also somewhat human readable, but also somewhat susceptible to collision.
- We could use a different surrogate key option such as a monotonically increasing integer value, like some old-school databases. But that leaves us with a distributed systems problem — make sure we don’t reuse the same value across multiple instances, without the overhead of distributed locking protocols.
- Another surrogate key option is a Universally Unique Identifier. UUIDs are guaranteed to be unique, but they’re hard to type and can start looking all the same to the human eye. To be honest, I really wanted to use the uuid type for the book examples, but ended up using strings (Cassandra’s “text” type) to represent the identifiers. This made the examples more readable and avoided a lot of typing for both me and my readers who were working along with the examples.
Perhaps there is some combination of attributes for our data that guarantees uniqueness, also known as a composite key. Often this is a good data modeling practice for identifying clustering columns in Cassandra, as mentioned above. But what if we decide to change the selection of attributes that define uniqueness?
Let’s look at some of these challenges in more depth.
Challenges of human-readable identifiers
The book sample takes a very simplistic approach to identifying points of interest — they’re identified by strings, both in the hotels_by_poi and pois_by_hotel tables. As my reader notes, this is not going to work well from a maintenance perspective. It’s also probably not going to scale very well. At some point, both users and maintainers of our application are going to have to decide if Paris means France or Texas, or if Baghdad is in Iraq or Arizona. Our model also doesn’t address any sort of text search features such as substrings or fuzzy matching. It is not contextually aware, so that if a user types “train station”, we have no idea where to begin in terms of sorting or prioritizing results.
To continue this investigation, let’s examine the scheme for hotel IDs which is implied in the book. As the reader notes, in Chapter 9 and elsewhere, I use example hotel IDs including “AZ123” and “NY229”. This assumes an ID scheme that is built on postal abbreviations for US states, concatenated with a 3-digit identifier for uniqueness. The advantage of using a scheme like this is that it is somewhat comprehensible to humans. If I have data that is labeled “AZ123”, I have some sense that it is for a hotel in Arizona. This is arguably of limited value to customers, but if I’m an operator of this application, I’ll likely come to be very familiar with many of these IDs and know which hotels they refer to, which may prove useful for diagnostic purposes.
However, this scheme also has obvious limitations:
- How will it extend to other countries? Can we use ISO two-letter country codes instead of state names?
- What if there are more than 1000 hotels in a given geographical region (however we decide to define a geographic region)? Then we’ll have to exceed the 3-digit format.
- What if my company acquires another hotel company, or integrates with an industry partner? What if that organization uses an entirely different ID scheme for hotels? Will it break my application?
- And possibly even more challenging than the previous question, what if the organization uses the same ID scheme? How will we resolve collisions?
The takeaway is that while our applications definitely need to be able to process these human-readable identifiers, there are significant risks involved in relying on them for unique database records.
Identity and the system of record
Let’s expand that discussion about interactions between systems a bit. In many cases, your system will not be the only one that cares about the identity of your data. Most systems have interfaces with other systems which may have their own ways of referencing data. Depending on the number and scope of these relationships, you may have a non-trivial architectural problem to solve.
As an example from the retail domain, consider that Amazon devotes a significant portion of their Seller API to managing multiple unique identifiers for products and the mappings between them, in acknowledgement that manufacturers, resellers, and Amazon itself will have different unique IDs for a particular product.
If you have an identifier that is owned by a system other than your own, you will want to make sure that you understand whether it is possible for that identifier to change. I once encountered a situation where an external system allowed product codes to change. We had been planning to use these product codes as unique identifiers in our application, but were forced to adjust our approach — thankfully, before we got too far into development!
Challenges of composite keys
We’ll now take a look at some of the challenges with using composite keys. However, I’d like to note first that there are some cases where a composite key is entirely appropriate. The available_rooms_by_hotel_date table is a great example:
CREATE TABLE hotel.available_rooms_by_hotel_date (
hotel_id text,
date date,
room_number smallint,
is_available boolean,
PRIMARY KEY ((hotel_id), date, room_number)
) WITH comment = 'Q4. Find available rooms by hotel / date';
There were no access patterns for availability data that require the ability to locate a particular row in this table by a single unique identifier. Instead, the typical access pattern for this table is for shopping requests, where a customer requests availability of rooms for a specified hotel and date range. In this case the design of the table is using the hotel_id and stay date as a composite key, and a typical query is based on either a single date or a range of dates. For example, the following query would return availability for two consecutive nights.
select * from hotel.available_rooms_by_hotel_date where hotel_id=’AZ123’
AND date>=’2017–03–24’ AND date<’2017–03–26’
Composite keys are often a great fit across a variety of application domains when you are storing time-based or time-series data and don’t have access patterns requiring a single ID.
However, let’s look at another case. When we look at the amenities_by_room table, the room is identified by a composite key consisting of a hotel_id and a room_number, for example: [“AZ123”, “101”]. Both elements are required to uniquely identify the room. What if I change my room numbering scheme? If in the future, I identify the need for an additional table when the website or mobile app needs to show textual descriptions and pictures of the rooms, how will I define the room ID?
Challenges of UUIDs
Having demonstrated the challenges of using natural and composite keys for unique identity, I’d like to take a look at one last category: surrogate keys. Since we discussed various surrogate key options in general above, let’s focus in on UUIDs.
UUIDs are clearly ideal for guaranteeing uniqueness, and are relatively compact in size at 16 bytes. The main challenge with UUIDs is human readability. I have often heard complaints from developers and operators that they don’t know what data they are looking at when tables rely primarily on UUIDs for identification of objects. While my reader didn’t find a hotel_id of “AZ123” to be very useful, it definitely conveys a lot more than “d604f44c-9576–4b88–91c7–1f186cf81b47” when diagnosing system issues. There are some good options for working around this challenge, which we’ll discuss below.
In terms of our physical schema design, there are actually multiple options on how to represent identifiers when using UUIDs. Using the CQL uuid type is an obvious option, but you can also use strings to store the identifiers. My advice would be to use the CQL uuid type since the UUID format requires less storage. The exception would be if there is a possibility that some or all of the identifiers could be other types, in which case the text type is most flexible. However, in my opinion, it is a best practice that applications control the generation of surrogate keys internally. In that way, the application can provide the guarantee that the surrogate key is a UUID. In many cases, these surrogate keys may not ever need to be exposed to application clients.
So, what kind of identifiers should I use?
Now that we’re done exploring options, it’s time to make some recommendations.
The way I think about things, if a data type is important enough to have its own table, the chances are good that it will be referenced by other data types at some point, unless it is time based data. If you model out enough of your application domain, you’ll see many of these cross-data type references start to emerge. A quick look at the example hotel data model yields the following list:
- Points of interest and hotels reference each other
- Amenities reference rooms
- The “availability calendar” references hotels and rooms
This quick analysis shows us that nearly all of the tables in our design have incoming references from other tables. The lone exception is the available_rooms_by_hotel_date table, which is time-based, as discussed above. So in a data model for a real application, my recommendation would be to consider creating UUID surrogate keys for points of interest, hotels, and amenities.
You can already see evidence of my preferred approach starting to peek through in the original design from the book, in which we have a hotelstable keyed by a hotel_id, and a hotels_by_poi table which uses the hotel_idas a clustering key. The only difference is transforming the attribute to the uuid type. Here’s a look at what an updated data model based on this approach might look like:
Hotel physical model — updated to use UUIDs as identifiers
As you can see, this results in adding new uuid attributes such as room_idand poi_id, and converting hotel_id to type uuid. You may have also noticed that my desire to give a room a surrogate key, I’ve added a rooms_by_hoteltable. The room_id can then be used as a key into the amenities_by_roomtable. Note the change here: there would be no need to have both the hotel_id and room_id attributes in the partition key, since they are both UUIDs. Instead, I’ve changed the hotel_id to be a regular column so that it can be used to navigate back to the hotel.
With respect to POIs, note that while we have addressed the principle of uniqueness, we haven’t entirely solved the potential problem of duplicate POI names, or POI names that are similar but not an exact match. We’ll work to fix that in a future article.
Now that we’ve worked through an example, let’s extract a few principles you can use to help think about how to represent identity in your data models:
- If the amount of data for a particular type will be relatively small in size, or the elements are a fixed set, you may find a simple natural key approach to be sufficient. (But you may be setting yourself up for a painful migration if you are wrong. And If the data is really small, I would ask if your use case really requires Cassandra.)
- Generally, a composite key approach works well for time-based or time-series data and a surrogate key is not required (although the composite key may consist of surrogate keys).
- <>In all other cases, I recommend using a UUID as a surrogate key for a data type, including instances where a data element is referenced from other elements. <>As much as possible, make sure your application maintains its own internal definition of identity so that you can confidently use the uuidtype for your surrogate keys.
One final point: using UUIDs as references between types does not limit your ability to use denormalization to provide additional attributes as context. For example, we could easily add the hotel_name to any of the several tables that reference a hotel_id, to support cases where the application would want a hotel’s name without having to do an additional query on the hotels table. However, it then becomes an application level responsibility to update those denormalized attributes across multiple tables when they are updated.
Identity and Microservices
The practice of establishing surrogate keys (UUIDs or otherwise) for most data types has another benefit: it decouples the relationships between different data types, such that all we need to access another element is a single ID. This decoupling lends itself naturally toward a microservice architecture in which each service owns a specific data type, including how the data is persisted. There are significant tradeoffs involved here, and we’ll devote our attention to those in the next article, where we’ll explore the intersection of data models and architecture.
My hope is that this series of articles will help you to build better data models using Cassandra and create applications that are extensible and scalable.
More Technology
View All
How to Create a Local LangChain Vector Database

Apache Cassandra 2024 Wrapped: A Year of Innovation and Growth

How We Built UnReel: An AI-Generated, Multiplayer Movie Quiz
