

One of the most misunderstood subjects in Apache Cassandra® usage is Batches. To set the stage we will need to take a look at how normal operations are handled in Cassandra.
In Cassandra insert, update, and delete operations are all handled in a very similar way. In one sense you can think about them all as inserts. This is because they all place some data on a node based on a partition key and clustering columns. In the case of an insert or update this data is simply the new data for that location. In the case of a delete, they place something called a tombstone or deletion marker in the correct location.
Due to this partition key clustering column method of data distribution, there is a requirement to denormalize your data in Cassandra. This is largely due to the fact that in the majority of cases, you end up with one table per query. Further complicating things is the fact that Cassandra doesn’t use a master node to handle requests. Each node can be a coordinator for any request meaning that multiple statements over multiple tables will almost certainly not be coordinated by the same node.
Consistency concerns start to arise when running operations over multiple tables with the same data. What happens if a single write fails? What happens if a delete doesn’t take? This is a simple look at a very real issue that many users face with Cassandra on a daily basis. Many organizations simply can’t take the risk that data will be out of sync and so at a glance Cassandra can look very scary. That is why in 2012 the batch statement was created.
What is a batch?
So what is a batch and how does it solve this distributed data problem? Simply put, a batch is an operation that takes a set of statements with common data that has been denormalized over many tables and runs all statements as a group from a single coordinator node. This means there is a pass-fail condition based on the batch statement as a whole not each individual statement on its own.
When a batch is executed the driver will take all the statements within the batch and package them up into a single operation. This operation will be sent to a single node in the cluster to act as the coordinator for that one set of requests. Success will then be reported on how many succeed and how many if any failed.
Batches also have a feature where they will retry in a much more aggressive manner than a normal query will. In order to have this feature, you must be using logged batches. Logged batches are the default if not specified. In the case of a logged batch, the batch log is replicated to 2 nodes and is replayed in the case of a failure. The batch log is only removed once the batch has succeeded or hints have been replayed. As one might imagine this type of operation comes at an additional cost but in cases where these stronger guarantees are needed the tradeoff can be worth it.
So in a situation where there are 2 tables that all contain some information on something like a video comment one is queried by a partition key of videoid and the other is userid. These tables might have the exact same data between them but have different structures for their primary key. If we modify a comment we want to modify both tables and we want to guarantee that both will be updated and all operations will succeed so that our data doesn’t get out of sync and break our application.
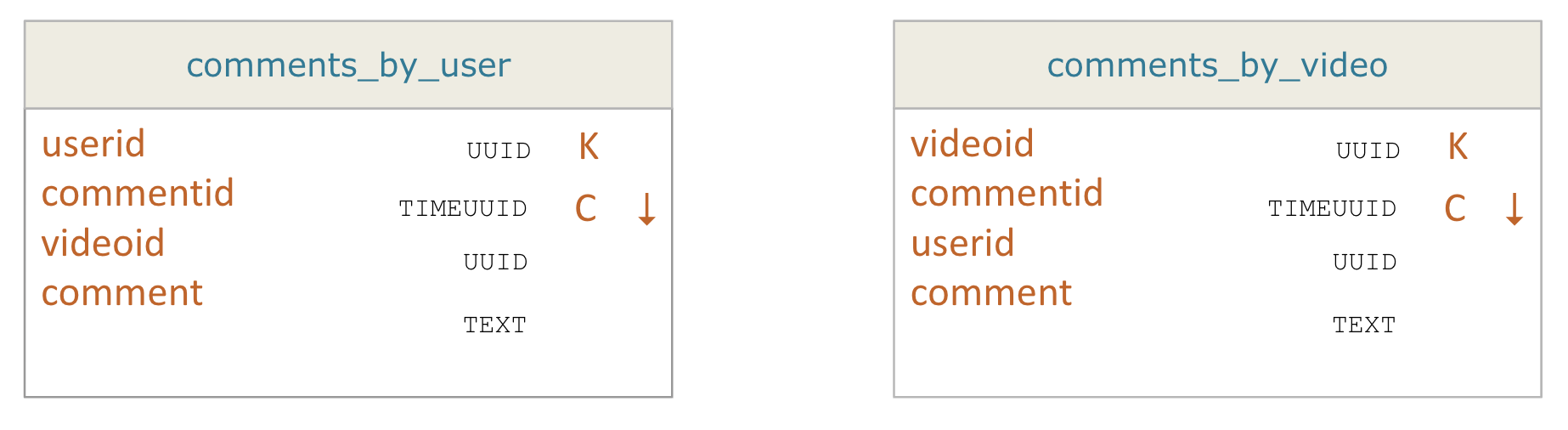
For these tables the insert statement would look like the following with all the data being the same between the two tables.
BEGIN BATCH
INSERT INTO comments_by_user (userid, commentid, videoid, comment
) VALUES (..., …, …, ...);
INSERT INTO comments_by_video (videoid, commentid, userid, comment
) VALUES (..., …, …, ...);
APPLY BATCH ;
Batches and data loading/query optimization
When most database people hear the word batch the first thing that pops into mind is a relational database and query optimization. In the Cassandra world this is simply not the case. The term batch is shared between both Cassandra batch and the relational world but that is where the similarity ends. As was discussed previously batches are used to keep denormalized data in sync across multiple tables that contain similar data. If we tried to package up a large number of requests into a single batch this would result in them being sent to and handled by a single coordinator node. This action would circumvent the load balancing that is used by the Cassandra driver and in many cases would result in that coordinator node being overloaded and timing out. In the Cassandra world everything is about spreading out the load consistently so that there are no limits to scalability. The driver is smart in how requests are routed and forcing a single node to be a pseudo master for a large number of requests just breaks things.
Logged vs unlogged
Now for the case of logged vs unlogged batches. When a logged batch is packaged up and sent out from the driver to the coordinator the first thing the coordinator tries to do is to replicate a batch log to two other nodes. This means that if for some reason the coordinator fails the batch can be replayed by nodes which logged the batch and the writes will still occur. The batch logs are stored in the local system keyspace and if a failure occurs during this log step, the batch will by default retry once and then fail. Only once the coordinator determines that the batch has been logged will it apply the statements within the batch. Once the coordinator determines that the write operations were successful, it will send a delete batchlog message causing the batchlog to be deleted on the replica nodes.This provides the set of operations with a strong guarantee that things will complete or not as a group but as mentioned before it is not a 100% guarantee as there are still edge cases where failures could result in partial data being written. All the extra steps that come with batches also come with extra cost. Each additional step in the process takes additional time and resources to complete so in many high velocity use cases logged batches might not be a good fit.
Unlogged batches do not use a batch log but still route all requests to the same coordinator as a single operation. As such it should be pointed out that an unlogged batch could be used to optimize queries over a single partition in small numbers. If using the TokenAware load balancing policy the requests will still be sent in a group to a valid replica node as the coordinator. The requests will be run and network traffic will be reduced as the batch is functionally a single request from the driver to the coordinator. All this said, when doing this keep the number of requests small, as it is easy to cause unbalanced load in the coordinator by sending too many requests at one time. This is a network optimization at the expense of extra resource load on the coordinator node.

Batches and Timestamps
Timestamps can be applied at a batch level to all operations in a batch. This is useful when there is a requirement for consistent timestamps over multiple denormalized tables. Similarly if a single request in a batch fails and is re-written from the batchlog it will still share the timestamp of the rest of the operations in the batch. There are use cases where this can be useful such as the timestamp being part of the Primary Key for some of the tables in the batch.

Conclusion
Batches are not atomic in the traditional sense as they have no rollback on failure. Since Cassandra works with eventual consistency there are cases where some of the batch could be applied and some still in process when a read request is serviced. Even though the batches will eventually succeed, the data returned in this window would not be correct from an application standpoint. There are also cases where logged batches might still fail part of their operation if multiple nodes fail in such a way as to end up needing to be replaced. In these cases you will end up with a part of the data out of sync. The good news is that an error is returned on the failure and due to upserts you can in most cases refire the batch. Also important to note is that if the batch fails it is a symptom of multiple nodes down and that is a much bigger problem that should be addressed, not a shortcoming of batches.
Batches are a very powerful tool in Cassandra. As with all things in the Cassandra world there are right and wrong ways to use them and they are by no means a silver bullet for every use case. They can have a massive impact on how requests are handled between the driver and coordinator. Batches can provide a very strong guarantee that all requests will complete. Lastly logged batches are a tradeoff between performance and data guarantee. Above all understand the impact and use them correctly.
If you are running into issues with batches and data loading or query optimization, visit DataStax Luna - enterprise support for Apache Cassandra.
More Technology
View All
How to Create a Local LangChain Vector Database

Apache Cassandra 2024 Wrapped: A Year of Innovation and Growth

How We Built UnReel: An AI-Generated, Multiplayer Movie Quiz
