

This is an excerpt from the DataStax whitepaper Data Modeling in Apache Cassandra®; which delves into how to choose the right data model for your Apache Cassandra® application in 5 easy steps. Click here to download the full whitepaper.
Intro
For web-scale applications, Apache Cassandra® is a favorite choice among architects and developers. It offers many advantages including performance, scalability, continuous availability, geographic distribution, and ease of management. Today, Cassandra is among the most successful NoSQL databases. It is used in countless applications from online retail to internet portals to time-series databases to mobile application backends.
While Cassandra is powerful and easy to use, having a well-designed data model is essential to meeting application performance and scalability goals. In this paper, aimed at technical people experienced with relational databases, we discuss five useful steps to realizing a high-quality data model for your Cassandra application.
How Cassandra Stores Data
Understanding how Cassandra stores data is essential to developing a good data model. Readers wishing to get a better understanding of Cassandra’s internal architecture can read the DataStax Apache Cassandra® Architecture whitepaper.
Apache Cassandra® Architecture
Read this white paper to learn how Cassandra was born, how it’s evolved, how it operates, and what DataStax Distribution of Apache Cassandra® adds to the equation.
Cassandra clusters have multiple nodes running in local data centers or public clouds. Data is typically stored redundantly across nodes according to a configurable replication factor so that the database continues to operate even when nodes are down or unreachable.
Tables in Cassandra are much like RDBMS tables. Physical records in the table are spread across the cluster at a location determined by a partition key. The partition key is hashed to a 64-bit token that identifies the Cassandra node where data and replicas are stored. The Cassandra cluster is conceptually represented as a ring, as shown in Figure 1, where each cluster node is responsible for storing tokens in a range.
Queries that look up records based on the partition key are extremely fast because Cassandra can immediately determine the host holding required data using the partitioning function. Since clusters can potentially have hundreds or even thousands of nodes, Cassandra can handle many simultaneous queries because queries and data are distributed across cluster nodes.
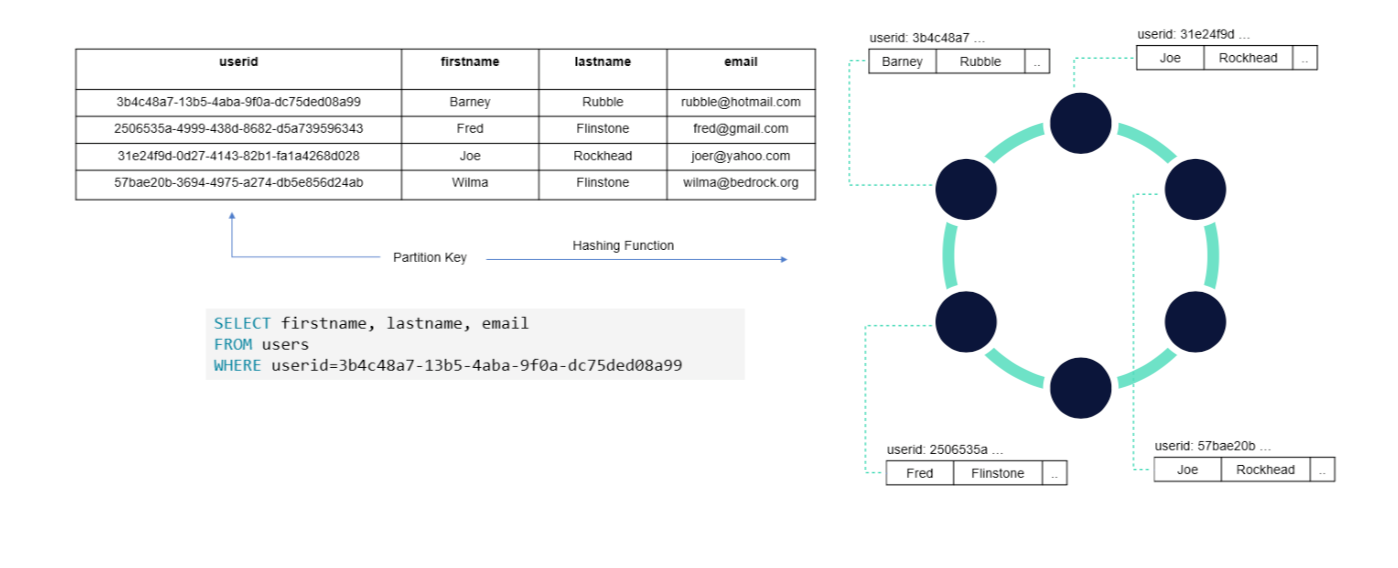
Figure 1 - How Cassandra Stores Data
Partition keys can be single columns or can be composed of multiple columns. Cassandra also supports clustering columns (discussed shortly) that control how data records are grouped and organized within each partition. Records in Cassandra are stored as lists of key-value pairs where the column name is the key.
Thanks for reading this excerpt from the DataStax whitepaper Data Modeling in Apache Cassandra®; tune in next week when we'll release another excerpt or click here to download the full asset.









