

Besides improvements to compaction and repair, 2.1 brings dramatic improvements to the core read and write paths. The two most important changes were:
- Adding response grouping to the CQL dispatcher, on a similar principle as Nagle's algorithm.
- Introducing the SharedExecutorPool for worker threads on replicas.
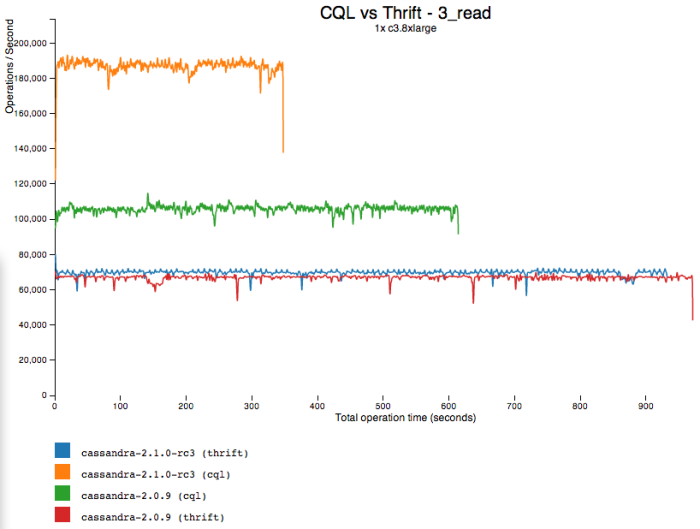
On reads, these combine for a 75% performance boost over 2.0 CQL, and 160% over Thrift:
On writes, we see a similar improvement -- 95% better than 2.0 CQL, and 150% better than Thrift:
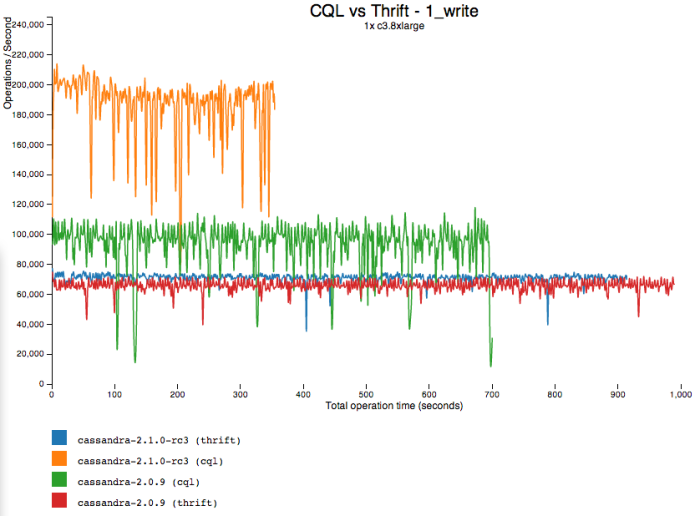
But wait! Why is write performance so inconsistent in 2.1? Writes are mostly cruising along at over 190k ops/s, but frequently dips as low as 120, so the average only works out to about 180.
It turns out that after writing a custom in-memory BTree to replace SnapTreeMap and removing the switchlock contention, writes on this 32 core VM are actually bottlenecked on the (single) commitlog disk now. We confirmed this by testing with durable writes disabled, but that's not a very useful scenario for production. So we're prioritizing commitlog compression and support for multiple commitlog volumes quickly.
Final thoughts:
- CQL delivering on its promise of a substantial performance boost over Thrift. Even if you only care about performance and not the productivity benefits of CQL, I strongly recommend against Thrift unless you are maintaining a legacy code base.
- Some environments will benefit more than others from the improvements here. EC2 seems particularly happy with the new executor pool; other hardware may see different gains. Our two year old, 8 core test machines with 6 SATA disks saw "only" a 50% improvement on reads and a 60% improvement on writes.






