Schema in Cassandra 1.1

Jonathan EllisTechnology

The evolution of schema in Cassandra
When Cassandra was first released several years ago, it followed closely the data model outlined in Google's Bigtable paper (with the notable addition of SuperColumns -- more on these later): ColumnFamilies grouping related columns needed to be defined up-front, but column names were just byte arrays interpreted by the application. It would be fair to characterize this early Cassandra data model as "schemaless."
However, as systems deployed on Cassandra grew and matured, lack of schema became a pain point. When multiple teams are using the same data, it's very useful to be able to ask "what data is in this table (or columnfamily)," without diving into the source of the code that uses it. And as more codebases share a database, it also becomes more useful to have the database validate that the birth_date column in one row is always an integer.
So, starting with the 0.7 release roughly a year ago, Cassandra has first allowed, then encouraged telling Cassandra about your data types. I've taken to describing Cassandra as "Schema-optional:" it's not required, and you can ignore it at first then go back and add it later if you'd rather, but it's a good habit to get into. Today, doing this in CQL looks familiar:
CREATE TABLE users (
id uuid PRIMARY KEY,
name varchar,
state varchar
);
ALTER TABLE users ADD birth_date INT;
(Using UUIDs as a surrogate key is common in Cassandra, so that you don't need to worry about sequence or autoincrement synchronization across multiple machines.)
The best of both worlds
Superficially it may sound like Cassandra is headed back where relational databases started: every column predefined and typed. The big difference is in the practical limitations of Cassandra's log-structured merge-tree storage engine, compared to RDBMS b-trees.
Without going into too much detail, traditional storage engines allocate room for each column in each row, up front. (Rows that have different sets of columns are grudgingly accomodated via nulls.)
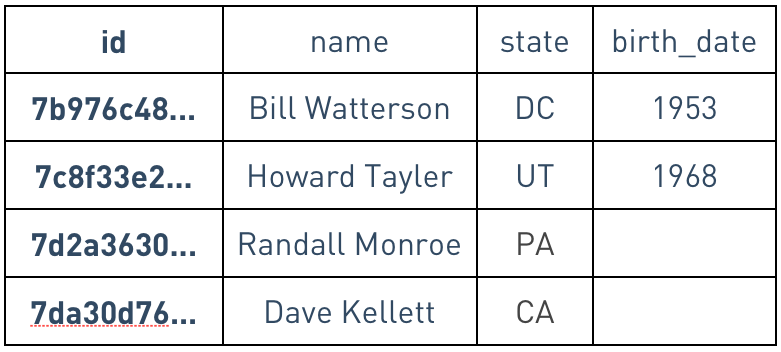
In a static-column storage engine, each row must reserve space for every column
In Cassandra's storage engine, each row is sparse: for a given row, we store only the columns present in that row. Technically this implies that we store the column names redundantly in each row, trading disk space to gain flexibility. Thus, adding columns to a Cassandra table always only takes a few milliseconds, rather than growing from minutes to hours or even weeks as data is added to the table with a storage engine that needs to re-allocate space row by row to accommodate the new data.
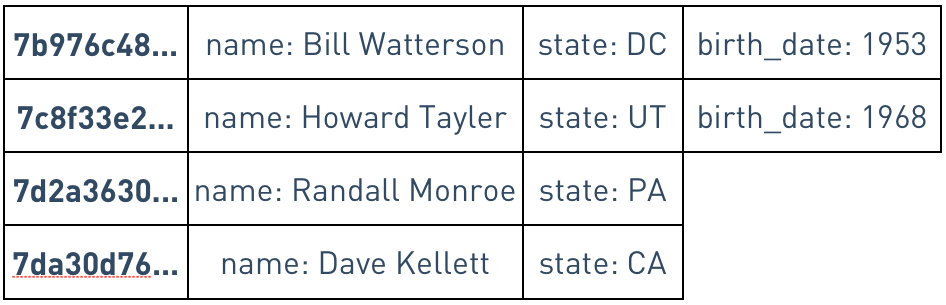
In a sparse-column engine, space is only used by columns present in each row
This also means that Cassandra can easily support thousands of columns per table, without wasting space if each row only needs a few of them.
Thus, Cassandra gives you the flexibility normally associated with schemaless systems, while also delivering the benefits of having a defined schema.
Clustering, compound keys, and more
Starting in the upcoming Cassandra 1.1 release, CQL (the Cassandra Query Language) supports defining columnfamilies with compound primary keys. The first column in a compound key definition continues to be used as the partition key, and remaining columns are automatically clustered: that is, all the rows sharing a given partition key will be sorted by the remaining components of the primary key.
For example, consider the sblocks table in the CassandraFS data model:
CREATE TABLE sblocks (
block_id uuid,
subblock_id uuid,
data blob,
PRIMARY KEY (block_id, subblock_id)
)
WITH COMPACT STORAGE;
The first element of the primary key, block_id, is the partition key, which means that all subblocks of a given block will be routed to the same replicas. For each block, subblocks are also ordered by the subblock id. DataStax Enterprise uses this property to make sure that SELECT data FROM sblocks WHERE block_id = ? is sequential i/o in subblock_id order.
Compound keys can also be useful when denormalizing data for faster queries. Consider a Twitter data model like Twissandra's. We have tweet data:
CREATE TABLE tweets (
tweet_id uuid PRIMARY KEY,
author varchar,
body varchar
);
But the most frequent query ("show me the 20 most recent tweets from people I follow") would be expensive against a normalized model. So we denormalize into another table:
CREATE TABLE timeline (
user_id varchar,
tweet_id uuid,
author varchar,
body varchar,
PRIMARY KEY (user_id, tweet_id)
);
That is, any time a given author makes a tweet, we look up who follows him, and insert a copy of the tweet into the followers' timeline. Cassandra orders version 1 UUIDs by their time component, so SELECT * FROM timeline WHERE user_id = ? ORDER BY tweet_id DESC LIMIT 20 requires no sort at query time.
(At the time of this writing, ORDER BY syntax is being finalized; this is my best guess as to what it will look like.)
Under the hood and historical notes
Cassandra's storage engine uses composite columns under the hood to store clustered rows. This means that all the logical rows with the same partition key get stored as a single physical "wide row." This is why Cassandra supports up to 2 billion columns per (physical) row, and why Cassandra's old Thrift api has methods to take "slices" of such rows.
To illustrate this, let's consider three tweets for our timeline data model above:
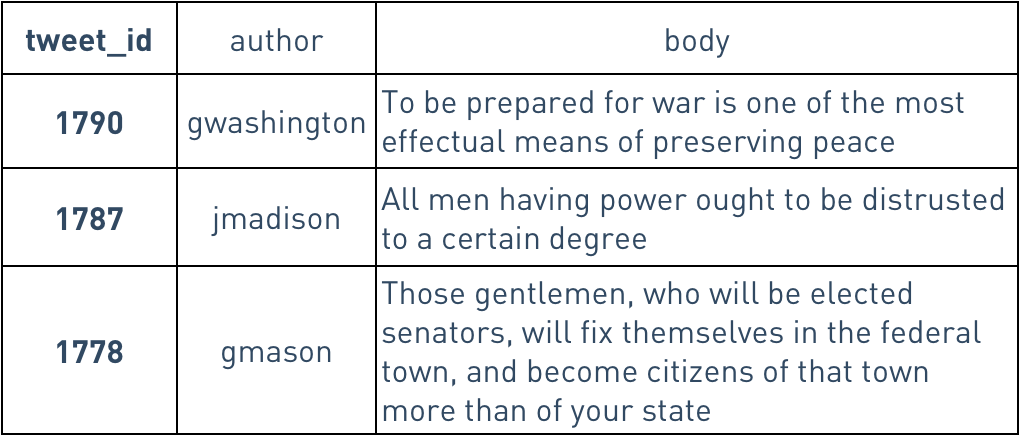
Raw tweet data
We'll have timeline entries for jadams, who follows gwashington and jmadison, and ahamilton, who follows gwashington and gmason. I've colored these rows by their partition key, the user_id:
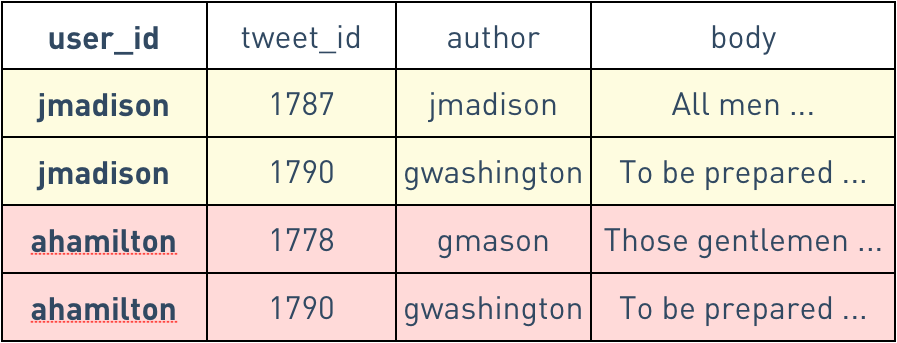
Logical representation of the denormalized timeline rows
The physical layout of this data looks like this to Cassandra's storage engine:

Physical representation of the denormalized timeline rows
The WITH COMPACT STORAGE directive is provided for backwards compatibility with older Cassandra applications, as in the CassandraFS example above; new applications should avoid it. Using COMPACT STORAGE will prevent you from adding new columns that are not part of the PRIMARY KEY. With COMPACT STORAGE, each logical row corresponds to exactly one physical column:

Physical representation of the denormalized timeline rows, WITH COMPACT STORAGE
SuperColumns were an early attempt at providing the same kinds of denormalization tools discussed above. They have important limitations (e.g., reading any subcolumn from a SuperColumn pulls the entire SuperColumn into memory) and will eventually be replaced by a composite column implementation with the same API. So if you have an application using SuperColumns, you don't need to rewrite anything, but if you are starting fresh, you should use the more flexible approach described above.
More Technology
View All
How to Build a Crystal Image Search App with Vector Search

Knowledge Graphs for RAG without a GraphDB

